
This page applies to developers. It provides examples of how to prepare data from different data sources so it's ready for process analysis.
OverviewCopy link to clipboard
Appian's data fabric gives you the power to unify data from different systems so you can connect to process data, regardless of where the data lives, and prepare it for process insights.
Each of the following sections provides an example of a different way to connect to process data and then prepare it for process insights.
If you're connecting to a database, check out:
- Example: Record events
- Example: Existing event table
- Example: CDTs and DSEs
- Example: External database
If you're connecting to a web service, check out Example: Web service. For Salesforce web services specifically, check out Example: Salesforce opportunities.
If you've captured data as comma-separated values (CSV), check out Example: Comma-separated values.
Example: Record eventsCopy link to clipboard
Configuring record events is the easiest way to capture new case and event data in a database. In this example, the Elliot Corporation wants to capture events for a financial client onboarding application.
As part of application development, the developer has already created synced record types for the core data in this app: Accounts, Customers, and Regions. The developer has also added relationships between these record types.
For the purposes of gathering case and event data, the Accounts record type is the case record type and has a one-to-one relationship with Customers. Customers has a many-to-one relationship with Regions. Through these relationships, a data steward can include information from the Customers and Regions record types in a process, providing a richer context of case data.
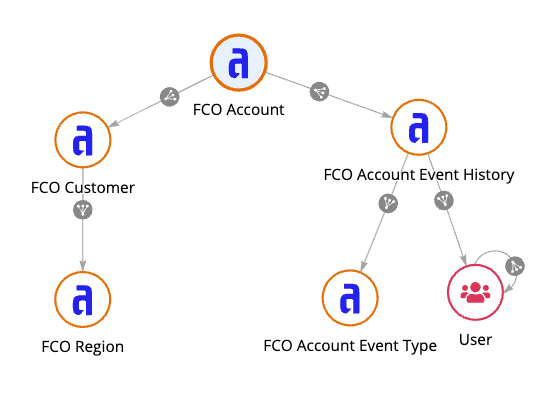

However, the application is currently missing an event history record type to capture and store events about accounts.
To capture event data in this application:
- On the Accounts record type, the developer configures record events by generating event record types.
- For the Types of Events, the developer specifies the types of events that can occur in the business processes. For example:
- Received Application
- Completed Pre-Onboarding Compliance Check
- Completed Know Your Customer (KYC) Review
- Completed Financial Document Verification
- Completed Financial Review
- Approved Application
- Completed User Account Provisioning
- Funded Account
- When the developer clicks GENERATE, two new record types are created:
- Accounts Event History record type, which will store information for events that involve the Accounts record type.
- Accounts Event Type Lookup record type, which stores the static list of event types, also known as activities.
-
The developer sets up a process model, where they configure a Write Records node to write case and event data at the same time. For example, the node writes events for situations like:
- The client submits the application (Application Received).
- An employee has reviewed the application (KYC Review).
- An employee has verified the client's documentation (Financial Document Verification).
As the process model runs, the node writes case data to the Account record type and event data to the Account Event History record type.
- In Process HQ, the data steward adds the process using data from the Accounts, Account Event History, Account Event Type Lookup, Customer, and Regions record types. Minimal-to-no data preparation is required. At most, the data steward might want to hide sensitive data from the Accounts record type like the account number.
Example: Existing event tableCopy link to clipboard
In this example, the Appian Retail company currently stores existing event data in a single database table, Retail Events. This table includes data from multiple processes, like order fulfillment, customer management, and employee management, all managed within the Appian Retail application.
For example:
- John Smith (customer) submitted an order.
- Jane Walker (employee) reviewed the order.
- John Smith updated his personal information.
- Jane Walker updated the account manager.
- Jane Walker promoted an employee.
- Jane Walker started a performance review.
Now, though, Appian Retail wants to analyze just their process for fulfilling customer orders. Their event data includes the required fields, so with some data preparation, they can use the data for process analysis. So that the data is only focused on order events, they can use part of the data in the Retail Events table as the source of a new Order event history record type.
In this example, the developer has already created a synced record type for Orders. For the purposes of process analysis, the Orders record type is the case record type.
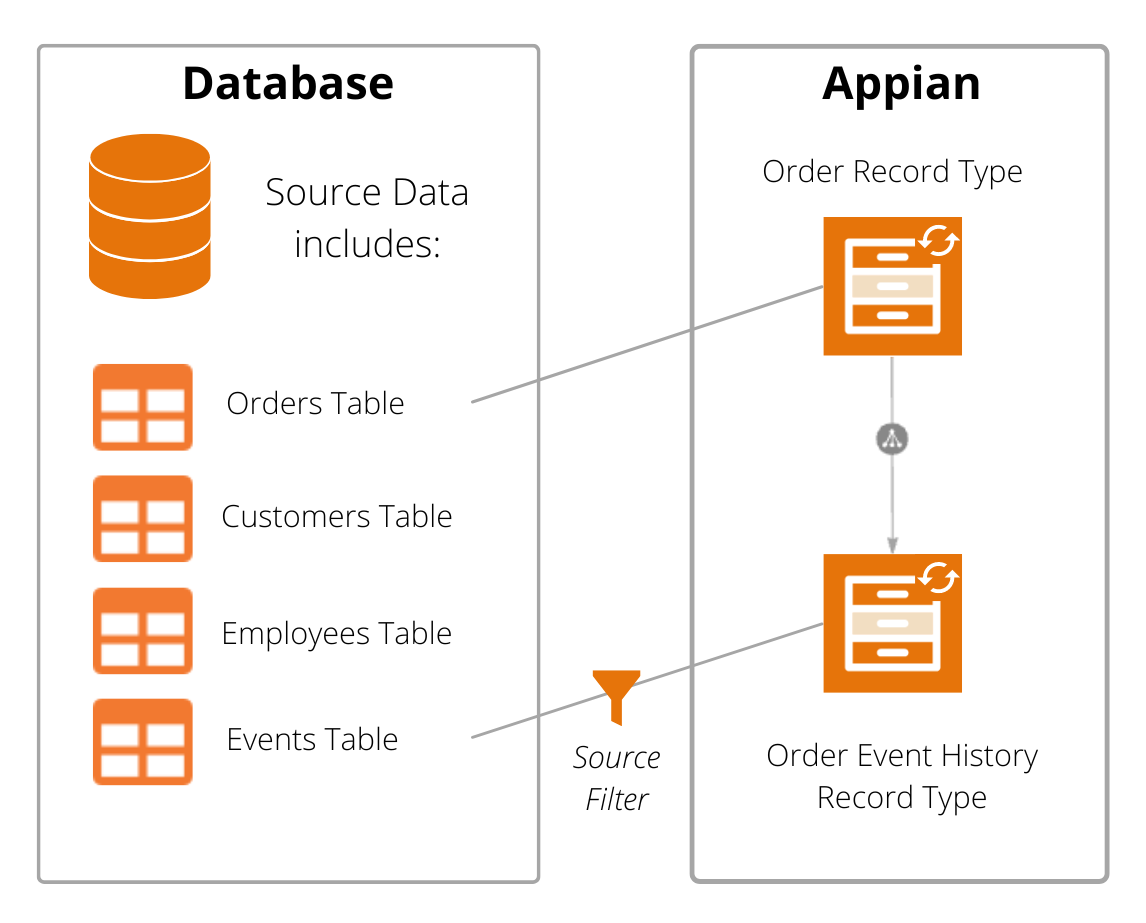
To connect to the existing Retail Events table and prepare it for process analysis:
- The developer creates a new synced record type called Order Event History using the Retail Events table as the source.
-
While configuring the source, the developer configures sync filters to only sync events that are relevant to an order.
In this example, the table includes a column (
processId) that specifies which business process an event relates to. The sync filter would limit events in the Order Event History record type to events withprocessIdequal to3(which represents the order fulfillment process). - The developer opens the Orders record type and creates a one-to-many relationship to the Order Event History record type. No other relationships or configurations are required to use this data in a process.
- The developer deploys the application to production.
- In Process HQ, the data steward adds the process using data from the Order and Order Event History record types.
Example: CDTs and DSEsCopy link to clipboard
In this example, the Acme Technical Services company uses a support case app to manage their support case data and the related events. Because their case and event data exceeds the row limit for synced record types, they use data store entities (DSEs) and custom data types (CDTs) to connect to the source database.
However, to analyze data using process insights, the data must be available in synced record types. Instead of refactoring the entire support case app, however, they can simply create synced record types to connect to the data they need, while leaving their current data structure intact.
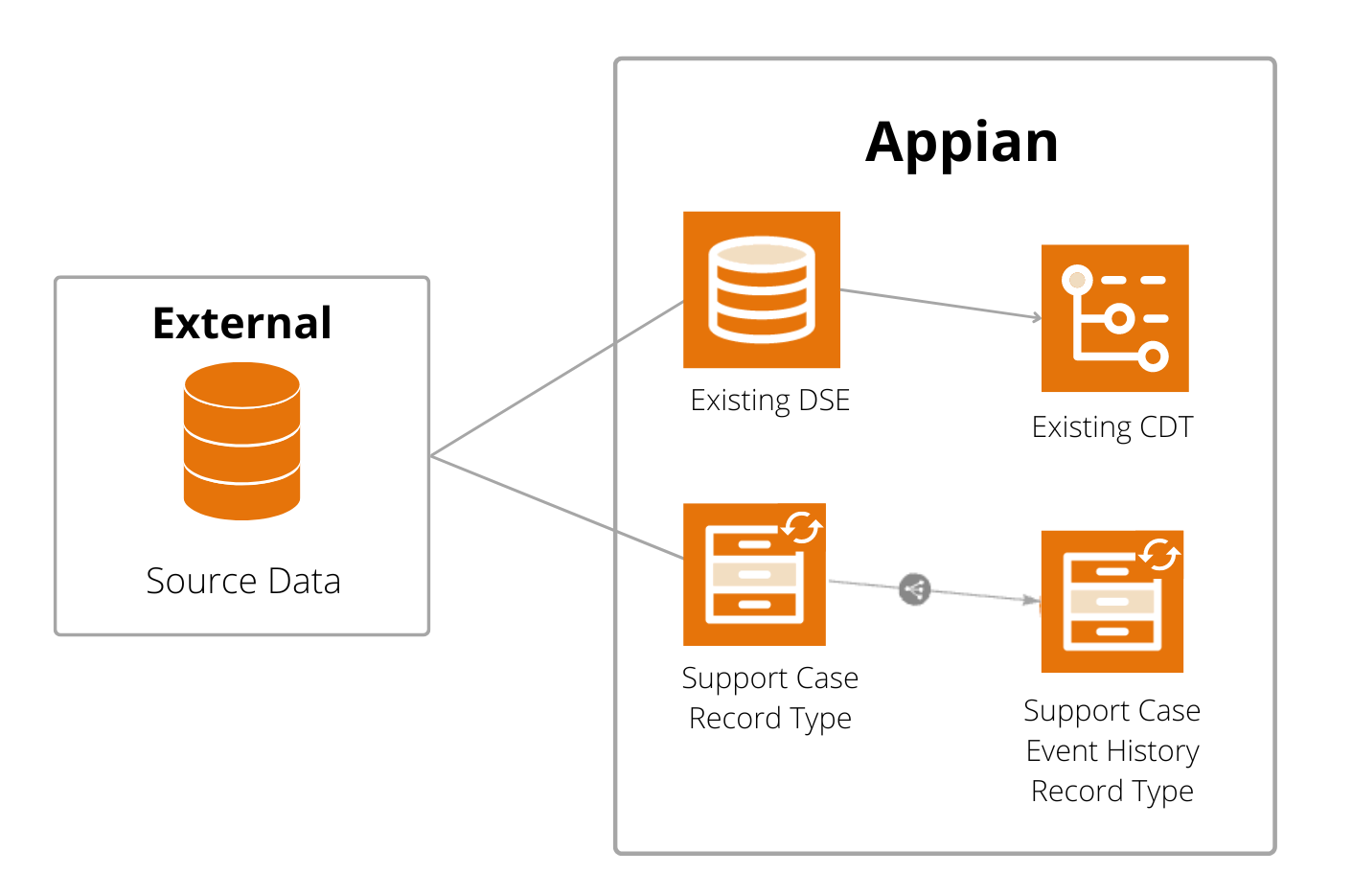
To connect to their existing database and prepare the case and event data:
- The developer creates a synced record type called the Support Case record type. This record type connects to the support case data stored in the Support Case table.
- While configuring the record type, the developer adds sync filters to prevent the record type from exceeding the row limit.
- The developer creates a synced record type called the Support Case Event History record type. This record type connects to the event history data stored in the Support Case Events table.
- While configuring the record type, the developer adds sync filters to limit the data to the necessary events.
- The developer creates a relationship between the Support Cases and Event History record types.
- The developer performs any necessary data preparation.
- The developer deploys the application to production.
- The data steward adds the process in Process HQ.
Example: External databaseCopy link to clipboard
In this example, we'll discuss the Bennett Manufacturing company, which stores its data in multiple databases. Data for its employee management app is stored in an Oracle database, while data for its vendor management app is stored in a Snowflake database.
By leveraging Appian's data fabric, they can connect and prepare data from any business process involving these applications.
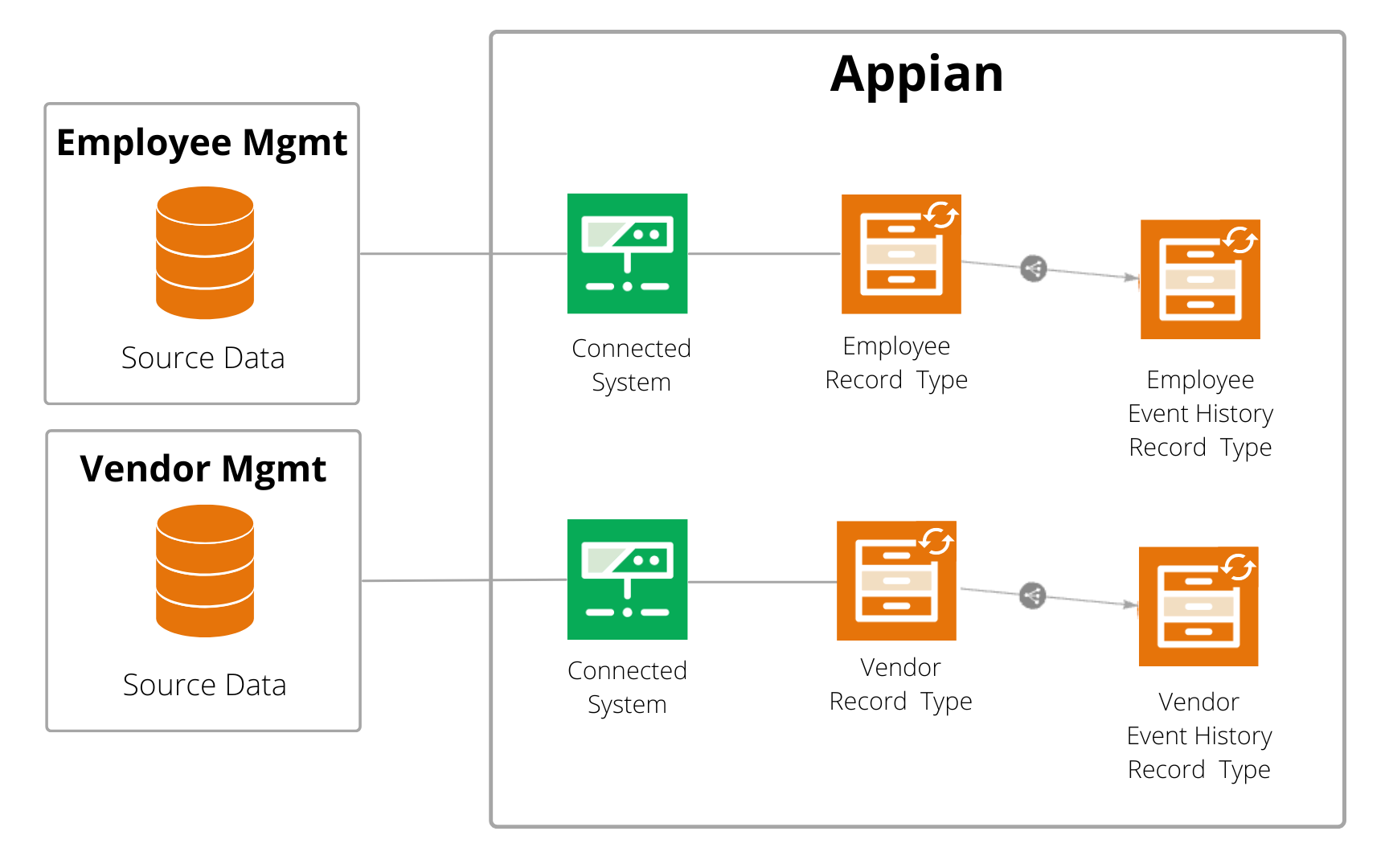
To connect to their process data and prepare it for process analysis:
- The developer configures a connected system to connect to each database:
- Employee management data is stored in one of Appian's supported databases, so they'll create a data source connected system.
- Vendor management data is stored in an unsupported database, so they'll create a custom JDBC connected system.
- For each application, the developer creates a synced record type for their case data. That record type uses the connected system to connect to the case table in the database.
- For each application, the developer creates a synced record type for their event data. That record type uses the connected system to connect to the event history table in the database.
- For each application, the developer creates a relationship between the case and event history record types.
- The developer performs any necessary data preparation.
- The developer deploys the application to production.
- The data steward adds the process in Process HQ.
Example: Web serviceCopy link to clipboard
Tip: Looking for help connecting to Salesforce specifically? See the Salesforce opportunities example.
In this example, the Fitzwilliam Software Solutions company uses Jira to track its internal software development lifecycle. Now they'd like to optimize their workflows using the data collected in Jira.
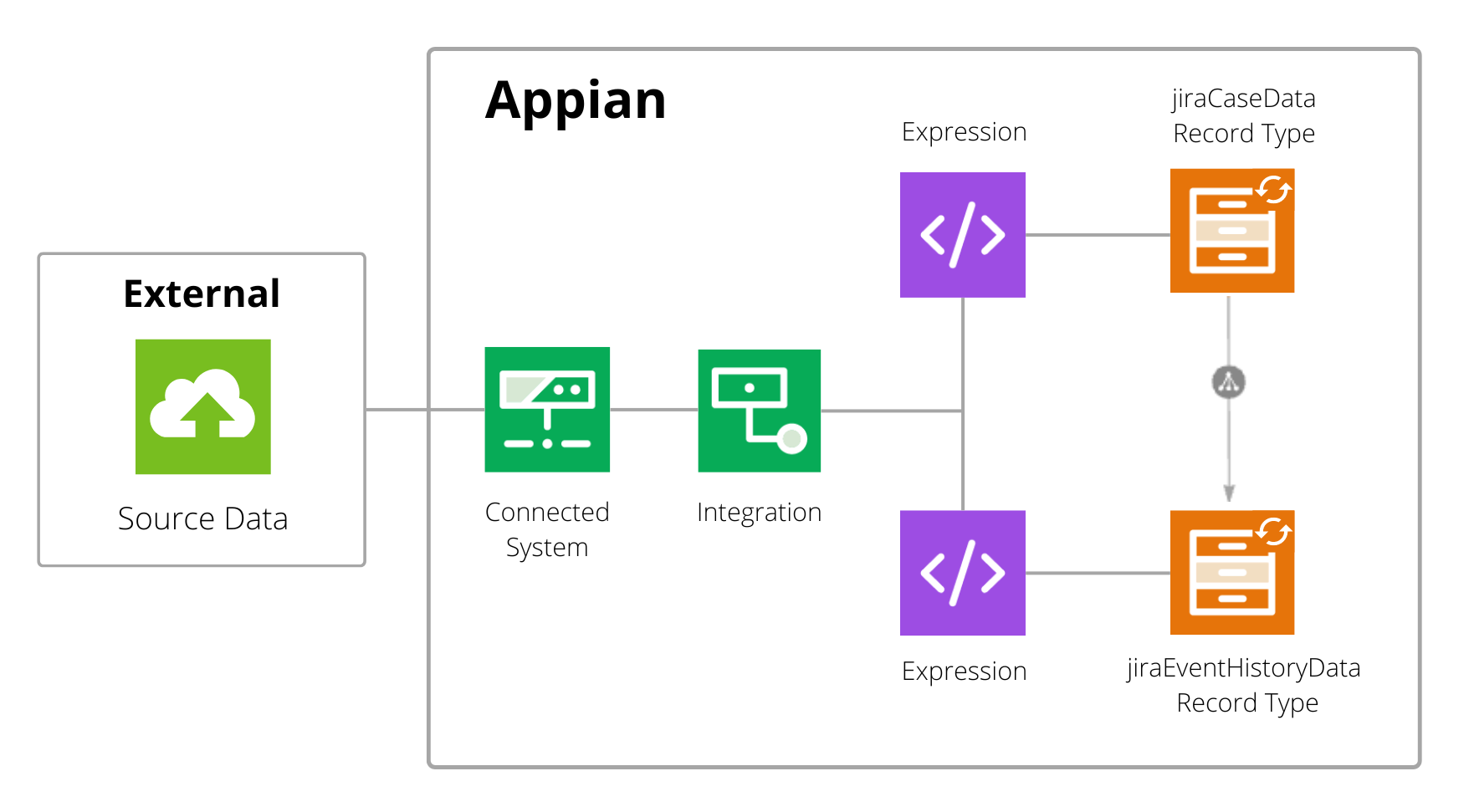
To prepare case and event data from this web service:
- The developer configures an HTTP connected system with the connection details to Jira.
- The developer configures an HTTP integration object using the connected system to retrieve data from Jira. This integration object will retrieve data from the Jira API.
- The developer creates a records data source called jiraCaseData to query the case data from the integration and configure batching.
- The developer creates a records data source called jiraEventHistoryData to query the event history data from the integration and configure batching.
- The developer creates a synced record type for their case data. That record type uses the jiraCaseData records data source to connect to the case data.
- The developer creates a synced record type for their event data. That record type uses the jiraEventHistoryData records data source to connect to the event history data.
- The developer creates a relationship between the Case and Event History record types.
- The developer performs any necessary data preparation.
- The developer deploys the application to production.
- The data steward adds the process in Process HQ.
Example: Salesforce opportunitiesCopy link to clipboard
Salesforce opportunities allow users to track and manage potential sales deals. In this example, the Global Corporation has enabled field history tracking in their Salesforce instance, so they can easily capture case and event data for those deals.
The Opportunity table stores the case data they need for process analysis.
The OpportunityFieldHistory table stores the history of changes to the values in the fields of each opportunity. Specifically, the field column tracks which fields in the Opportunity table were updated. To extract an event history from this larger history, we only want to sync data where the field value is stageName or created.
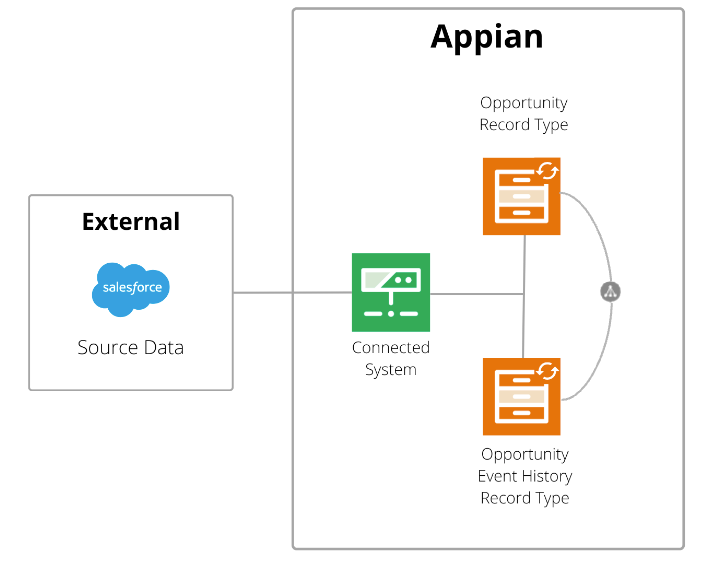
To prepare case and event data from Salesforce opportunities:
- The developer configures a Salesforce connected system.
- The developer creates a record type called the Opportunity record type:
- Selects Salesforce as the data source for the new record type.
- Enables data sync.
- Chooses the Salesforce connected system.
- Selects the Opportunity object from Salesforce.
- Configures sync filters to only sync opportunities from the last six months.
- Maps and renames record fields as appropriate, and add display names and descriptions to provide user-friendly field names for Process HQ users.
- Assigns Data Steward permissions to at least one user or group, so that this record type can be used in a process.
- The developer creates a record type called the Opportunity Event History record type:
- Selects Salesforce as the data source for the new record type.
- Enables data sync.
- Chooses the Salesforce connected system.
- Chooses the OpportunityFieldHistory from Salesforce.
-
Configures the following sync filter to only sync data from the OpportunityFieldHistory table where the
fieldvalue isstageNameorcreated:Property Value Field fieldCondition inValue {"StageName", "created"} - Maps and renames record fields as appropriate, and add display names and descriptions to provide user-friendly field names for Process HQ users.
- Assigns Data Steward permissions to at least one user or group, so that this record type can be used in a process.
-
On the Opportunity Event History record type, the developer creates a sync-time custom record field to extract the name of the opportunity stage that changed. They'll call the field, ActivityName, and uses the following expression:
1 2 3 4 5
if( rv!record[recordType!Sales Opportunity History.fields.field] = "created", "Created", rv!record[recordType!Sales Opportunity History.fields.newValue] )
Copy- Since there is no stage captured when an opportunity is initially created, this example sets the
ActivityNametoCreatedwhenever thecreatedfield is changed. - For all other changes to the opportunity, this example sets the
ActivityNameto the value in thenewValuefield.
The result is a single custom record field with values like,
Created,Prospecting,Qualification,Needs Analysis, etc. - Since there is no stage captured when an opportunity is initially created, this example sets the
- In the Opportunity record type, the developer adds a one-to-many relationship from the Opportunity record type to the Opportunity Event History record type, using the
Idfield from the Opportunity record type and theOpportunityIDfield from the Opportunity Event History record type as the common fields for the relationship. - The developer deploys the application to production.
- The data steward adds the process in Process HQ, using the following settings:
- For Case Record Type, select the Opportunity record type.
- For Event History Record Type, select the Opportunity Event History record type.
-
For event data, map the following required fields:
Field Map To OpportunityId Case ID ActivityName Activity CreatedDate Start
Example: Comma-separated values (CSV)Copy link to clipboard
In this example, the Peak Properties company stores data about the corporate and retail properties it manages in a legacy system that does not support API connections.
To work with that data, they export it from the legacy system to multiple CSV files. The properties.csv file stores data about the properties (the case data), while the propertyEvents.csv file stores data about management actions completed for those properties (event history data).
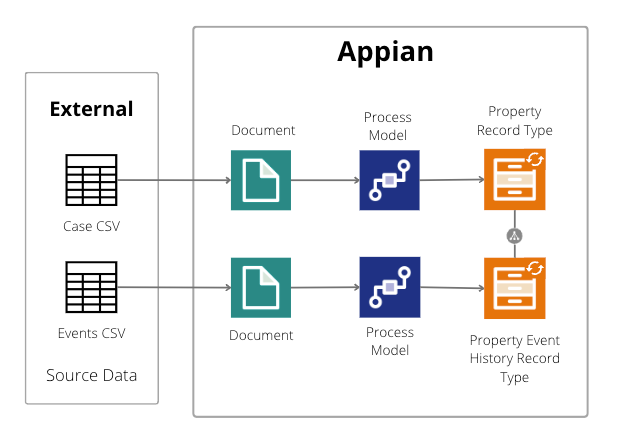
Note: To keep the recipe simple, we will not deploy these changes to a different environment; instead, we'll simply import the data into a development environment and access Process HQ from that environment.
To prepare case and event data from these CSV files:
- A system administrator adds the Excel Tools plug-in to the environment.
- The developer reviews both the
properties.csvandpropertyEvents.csvfiles. If each file does not have a unique ID column, the developer adds a blank column to the file. This blank column will be used as the ID field in the record type. -
The developer creates a case record type (Property) and an event history record type (Property Event History) as follows:
- Creates a new record type.
- Configures the source of the record type by generating a source. The source database table is automatically generated when they finish creating the record type.
- Adds fields for each column in the CSV file. The field names must be exactly the same as the CSV columns.
-
The developer creates two document objects, one for the
properties.csvfile and one for thepropertyEvents.csvfile. During this step, they will automatically generate a constant for each document. -
The developer creates a process model to import the
properties.csvvalues into the database:- They drag the Import CSV to Database smart service to the canvas.
-
On the Data tab for the smart service, they set the inputs as follows:
Input Value Set To C S V Document The name of the generated constant. Database Source Name The name of the database. In this example, Peak Properties is using the Appian Cloud database, so this value is "jdbc/Appian".Delimiter A comma ( ",").File Has Header "true"Table Name The name of the database table generated from the Property record type. -
On the Data tab, they set the outputs as follows to allow for debugging:
Output Target Set To Error Message Save to a new process variable. Success Save to a new process variable.
- The developer creates a process model to import the
propertyEvents.csvvalues into the database, using the same steps as they did for theproperties.csvfile. - The developer runs each process so that the system imports the data from the CSV files into the current environment.
- The developer triggers a manual full sync on the Property and Property Event History record types.
- The developer creates a one-to-many relationship from the Property record type to the Property Event History record type.
- The developer performs any necessary data preparation on each record type.
- The data steward adds the process in Process HQ.
This example involves a single environment. If you're deploying to another environment, you would need to perform additional steps. For example:
- Add the Excel Tools plug-in to all impacted environments.
- Save the generated database scripts when you configure the source of your record types.
- Add a timer event on the process models to import the CSV data on deployment.
- Set up a scheduled full sync on both record types so they sync the CSV data.
- Deploy your application to production.