
As you train your skill, you'll create one or more models. Each time you train a model, you'll see metrics to help show you how well it is able to fulfill its purpose. There is no single metric that can tell you that your model is ready to use in production. Instead, you'll want to evaluate this data based on your use case and consideration of how your process might be impacted.
This page explains the metrics you'll see during model training, how to interpret them, and how to use them to evaluate if the model meets your requirements.
Training files vs. test filesCopy link to clipboard
As training begins, the model divides the sample files into two groups:
- The model uses training files to learn about the documents or emails you expect to encounter in production. From the set of samples you provided, the model selects a few files and analyzes the characteristics of those files to learn about how to classify it or extract fields within it. For example, if the model identifies that most of your sample documents for the Invoice document type contain an Invoice No. field, it can use this information when testing.
- The model uses test files to apply what it has learned about the files and determine if its predictions are correct. The test files are the remainder of samples you provided, not used for training. If you uploaded 10 sample invoices and 7 were used for training, then 3 are used for testing.
This split between training files and test files occurs when your model begins training. The samples are split into the two groups randomly each time you train a model.
Which metrics are available?Copy link to clipboard
The metrics you'll see reflect the model's performance classifying or extracting values from test files.
Classification AI skillsCopy link to clipboard
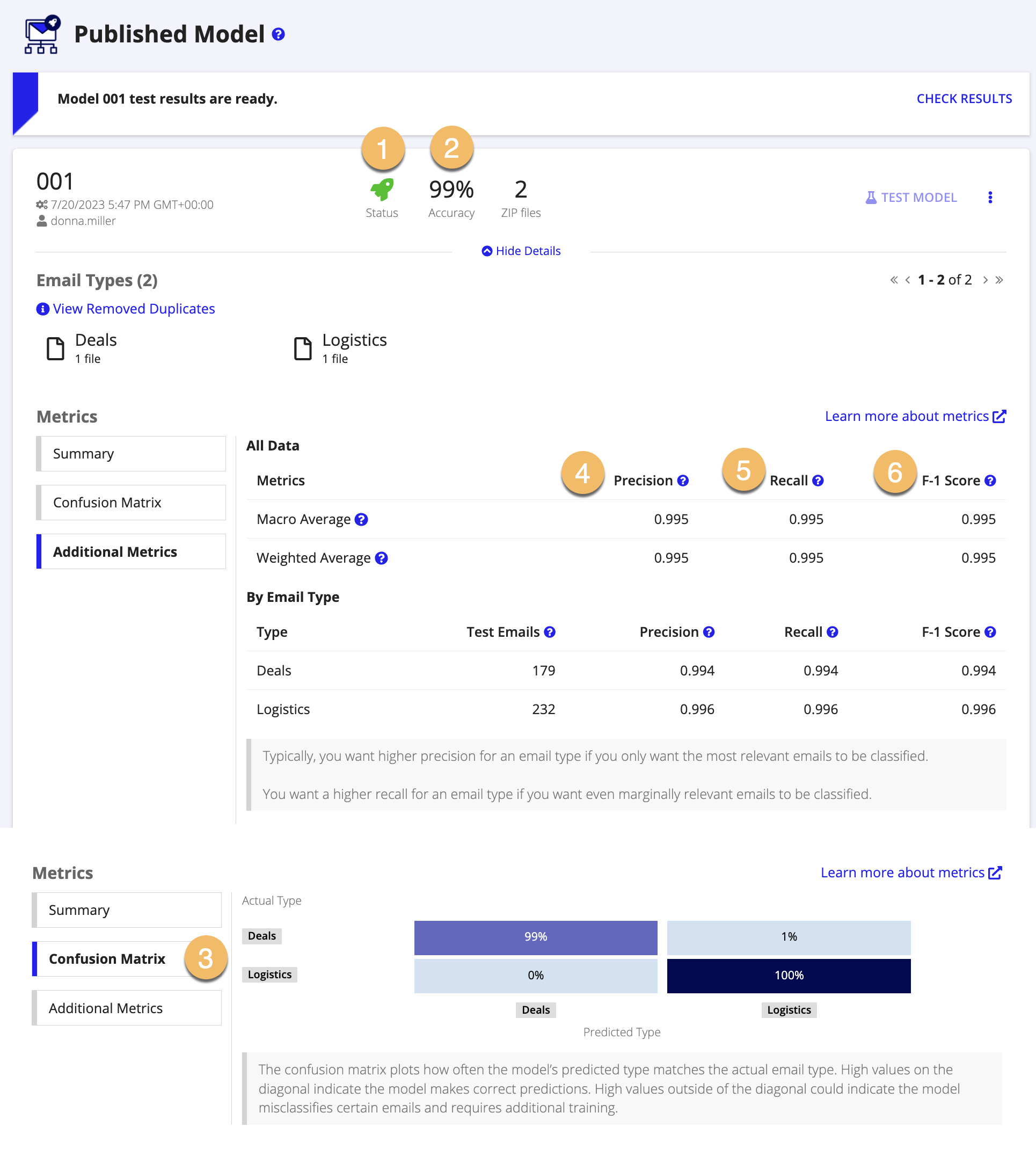
Each time you train a model in the document classification or email classification AI skill, you'll see the following metrics:

Extraction AI skillCopy link to clipboard
Each time you train a model in the document extraction AI skill, you'll see the following metrics:
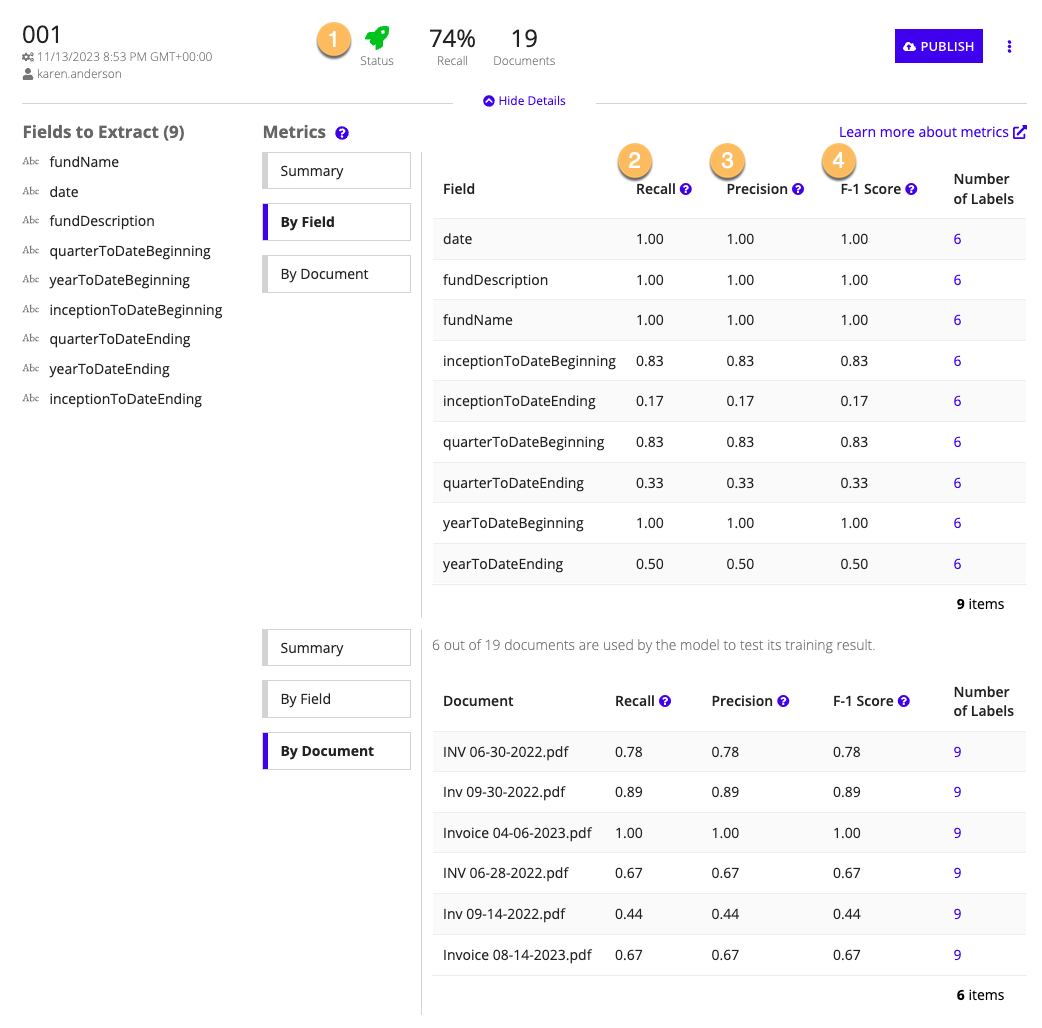
You can view these metrics By field or By document. The By field view shows the aggregated metrics for each field wherever it appears across the sample documents you used to train. The By document view shows aggregated metrics for how the model performed when extracting data from each one of the documents you uploaded.
In either view, you can click the value in the Number of Labels column to see the actual value vs. the extracted value during training.
How metrics are calculatedCopy link to clipboard
Before you can act upon these metrics, it's important to understand what each one means. First, let's recap some of the key concepts:
- Prediction or Predicted type: For each item that the model analyzes, it makes a prediction for what it is. Classification models make predictions about document types, while extraction models make predictions about fields. If a classification model predicts that a document is an invoice, then invoice is the predicted type.
- Actual type: To determine if the prediction is correct, the predicted type is compared to the actual type, or the item's type in reality. If the actual type (invoice) matches the predicted type (invoice), the model predicted the type correctly.
Now that we've refreshed our memories, we can start to evaluate whether the model's training results meet our needs:
StatusCopy link to clipboard
A model can be in one of five states:
- Draft: You created the model, but training hasn't started yet.
- Training in progress: The model is currently using the sample data set to learn and practice making correct predictions.
- Training complete: The model successfully finished training.
- Training failed: The model didn't successfully finish training. You may want to try again using different or additional representative data.
- Published: The model is available for use in your processes. If this skill is being used in a process model via a smart service, this is the model that will be called. Only one model can be published in an AI skill.
AccuracyCopy link to clipboard
Available as a training metric in document classification and email classification AI skills.
Accuracy is the ratio of correct predictions to total predictions, expressed as a percentage.
Accuracy is a broader metric than precision and recall, and it gives you an idea of how many total correct predictions the model made.
Accuracy includes true positives (correctly predicting that the document is part of a certain type) and true negatives (correctly predicting that the document isn't part of a certain type).
When is accuracy useful?: When your model classifies documents or emails in roughly equal numbers.
ConfidenceCopy link to clipboard
Available as a training metric in document classification and email classification AI skills.
Tip: Download the Prediction Result CSV to see the model's confidence score for each classification prediction made during training. This CSV is not available in document extraction AI skills.
The confidence score measures how sure the model is of its prediction. A confidence is calculated for each prediction the model makes.
Most decisions (made by humans or computers) can vary in confidence. If someone asked you, "what's 2 + 2?" and you answer "4," your confidence in that answer is probably very high. But if someone asked you, "what did you eat for lunch last Tuesday?" you might not be so sure of your reply. "I think I had pizza" indicates you aren't very confident in your answer. Machine learning models apply the same confidence to their predictions.
In training and in production, the model outputs a confidence score for each prediction it makes. The Classify Documents, Classify Emails, and Extract from Document smart services include a Confidence threshold output that you can configure to meet your requirements. This way, you can configure the process to proceed only when the model's confidence in a prediction is above the threshold value you set.
How is accuracy different than confidence?Copy link to clipboard
Confidence and accuracy are similar but distinct concepts and it's important to not confuse them. Confidence is determined per prediction, whereas accuracy is an average that's determined from the entire data set.
To understand the difference between accuracy and confidence, consider the following example:
You've created a model to recognize and classify two document types: invoices and purchase orders. During training, you uploaded 100 examples of invoices your business receives. The model uses 65 documents as training documents and 35 as test documents. The model learns from the 65 training documents, and then puts its knowledge to the test with the 35 test documents.
Of those 35 test documents, the model positively identifies 27 of them as invoices and the remaining 8 as purchase orders. Because this is training data, we (and the model) know that all 35 are invoices.
Looking back at the equation for accuracy, this model's accuracy is (27 / 35) * 100, or 77%.
Next is confidence. Confidence measures the probability the model will return a correct prediction. However, 100% confidence doesn't mean that the model will definitely return a correct prediction. Rather, confidence is the model's estimation at the likelihood the prediction is correct – not the actual result. Let's break it down by continuing our example:
Confidence is calculated for each document. Let's say the model is analyzing a document called acme_receiving.pdf. The model's average accuracy for predicting an invoice or a purchase order is 77%, so we can expect that the model will do reasonably well predicting the document's type.
Based on what it's learned about invoices and purchase orders, the model predicts that this is an invoice. However, the model's analysis only picked up on some signals that this document is an invoice. Based on those traits, the model is fairly confident this is an invoice and gives it a confidence score of 70%.
Next, the model analyzes a document called stock_request.pdf. This time, the model recognize some sure signs that this is a purchase order, which it learned during training. For one, the label "purchase order" appears at the top. During model training, every example purchase order had this label too. Other labels, like "description," "unit price," and "quantity" also appear here and are strong indicators of this document being a purchase order. Based on this information, the model classifies this as a purchase order with a confidence score of 90%.
Both predictions are true positives: the first document is indeed an invoice and the second one is a purchase order. But the model was more confident when it came to the purchase order, because it had more experience identifying similar documents in the past.
Accuracy and confidence are important for some use cases. Jump to Evaluating the data to learn more.
Confusion matrixCopy link to clipboard
Available in document classification and email classification AI skills.
To view the Confusion Matrix, select the All Data view within the metrics.
The confusion matrix visually represents the division of predicted and actual types. The confusion matrix grows larger based on the number of document or email types within the model.
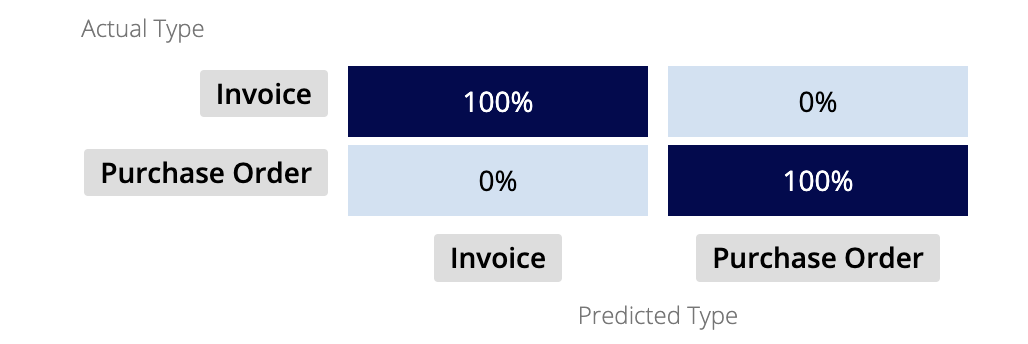
For example, in the image above, the two types (invoice and purchase order) are represented on both axes: predicted and actual. This creates four scenarios to measure:
- The model predicted the document is an invoice, and it is an invoice.
- The model predicted the document is an invoice, and it is an purchase order.
- The model predicted the document is a purchase order, and it is a purchase order.
- The model predicted the document is a purchase order, and it is an invoice.
We want the actual type to match the predicted type, so we look for higher numbers in the cells on the diagonal. These are the cells which overlap predicted and actual type, indicating a match.
Macro averageCopy link to clipboard
The macro average is mean of the metrics across all data types. It doesn't consider how many samples of each email or document were added for training.
Weighted averageCopy link to clipboard
The weighted average is the mean of the metrics across all types, but it also takes into account the number of documents that were uploaded per document or email type.
PrecisionCopy link to clipboard
Precision is the number of true positive predictions the model made.
The metric only considers the number of correct predictions the model made regarding a certain type or field. It doesn't include correct predictions for documents or emails that aren't part of a certain type, nor does it consider correct predictions that the model didn't make (false negatives).
For example, a model is given 10 documents and tasked with identifying how many of them are invoices. There are 4 invoices in the set of documents to classify, but the model positively identifies only 3 as being invoices. However, those 3 identifications are correct. In this example, the model's precision is 1.0 because all of its predictions were correct, even though it didn't identify all of the invoices.
Precision is closely related to recall, and together they calculate the F-1 Score.
When is precision useful?: When you want your model to avoid making false positive predictions.
- Classification example: you want to classify personal loan applications and business loan applications. Because business loan applications take many more resources to process, you want to avoid the model making false positive predictions for this document type. You'll want to pay attention to the model's precision making predictions for business loan applications.
- Extraction example: you want to extract data about invoice issue dates and due dates. If the model extracts the issue date when it means to extract the due date, the invoice appears past due. An automated process model notifies finance department of a past due invoice, which could be distracting if it's incorrect. In this scenario, you'll want to pay attention to the model's precision at extracting the due date field.
RecallCopy link to clipboard
Recall is the number of actual correct predictions a model made. Unlike precision, recall also considers the number of correct predictions the model didn't make.
For example, a model is given 10 documents and tasked with identifying how many of them are invoices. There are 4 invoices in the set of documents, but the model identifies only 3. However, those 3 identifications are correct. In this example, the model's recall is .75 because it missed predicting one of the invoices.
Recall is closely related to precision, and together they calculate the F-1 Score.
When is recall useful?: When you want your model to avoid making false negative predictions.
- Classification example: you want to classify personal loan applications and business loan applications. Because personal loan applications contain personal information that is protected by law, you want to avoid the model making false negative predictions for this document type, so this information isn't exposed to personnel in other departments that look at the business loan applications. You'll want to pay attention to the model's recall making predictions for personal loan applications.
- Extraction example: you want to extract data from personal loan applications to save in the system. After the data is saved in Appian, anonymized applications are reviewed by analysts for completeness and credit-worthiness. One piece of anonymized data is the applicant's social security number. You want recall to be higher for this field so that the model properly recognizes and extracts it, rather than accidentally identifying it as a non-sensitive piece of data, like a phone number.
F-1 scoreCopy link to clipboard
A metric used to measure accuracy in machine learning. The F-1 score (aka F-score) is a quick way to understand the model's ability to fulfill its purpose and make correct predictions. It is computed using precision and recall.
When is the F-1 score useful?: When your model classifies documents or emails in unequal numbers.
Evaluating the dataCopy link to clipboard
The flexibility of the AI skill means that there is no one-size-fits-all solution. The results of model training are subjective, meaning that you'll need to determine if the metrics meet your requirements. As you evaluate the results of training you'll want to consider the following:
- Where does classification or extraction fit in the process?
- What is the impact of an incorrect prediction?
- Am I more concerned about false negatives or false positives?
The answers to these questions can help you focus on different training metrics.
ExampleCopy link to clipboard
For the sake of demonstration and to help answer some of these questions, we'll use an example from a fictional company: Acme Insurance.
Acme Insurance offers vehicle insurance to customers. To file a new claim, a customer submits an online form. The customer can upload supporting paperwork (such as police reports, repair shop quotes, medical bills, and rental car bills), or they can request those organizations/businesses to send the documents directly to Acme.
After a customer files a claim, their case is automatically assigned to an adjustor in the state of their accident. The adjustor reviews the claim details and determines if any documentation is missing. If the claim has all of the necessary documentation, the adjustor creates a summary report to send to the at-fault party's insurance company to begin negotiations for reimbursement. If the claim is missing documentation, the adjustor reaches out to the customer (or businesses) to request it. In both cases, an automated process also extracts key data from the claim's supporting documents.
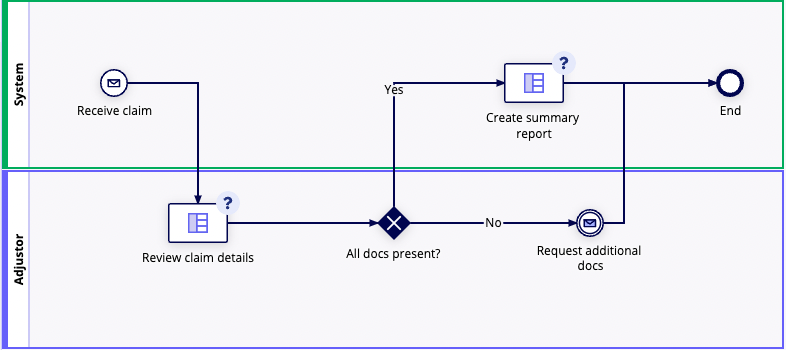
The adjustor takes special care with medical bills, prescriptions, and other sensitive information, since Acme is legally bound to not share this without the explicit permission of the customer first. Upon extraction, this data is also saved in a record type with extra security configured.
Where can AI help in this process?Copy link to clipboard
The adjustor spends a lot of time manually reviewing each incoming claim to see if the supporting documents are attached. On average, it takes an adjustor 15 minutes per incoming claim to review it for completeness. If the adjustor spent their 8-hour work day on this, they would get through roughly 30 new claims a day. Acme Insurance decides to pilot an AI project to see if they can reduce the amount of manual review each adjustor has to do.
The Acme developer gets started on a model to classify the following document types that are attached to incoming claims:
- Police reports
- Towing bills
- Repair estimates
- Medical bills
- Prescription bills
- Rental car bills
Now that we have a sense of the use case, we can discuss the evaluation questions:
- Where does classification fit in the process? Classification will help Acme automatically check if the appropriate documentation is attached to a claim. If the docs are, then the adjustor is notified to proceed assembling a claim summary to send to the at-fault driver's insurance company. If the docs aren't, then the customer needs to provide contact information for those individuals or businesses.
- Where does extraction fit in the process? Extraction helps Acme compile the data into a record type that allows adjustors and other Acme employees view data that's relevant to their job duties. Sensitive information needs to be properly captured so that personally identifiable information is only available to individuals who need it.
- What is the impact of an incorrect prediction? It depends. If the model incorrectly classifies a medical bill or prescription as anything else, then it might accidentally make its way into the packet that the adjustor assembles and sends to the other insurance company. The consequences of sharing that information, even accidentally, are high because Acme might be violating the customer's legal right to privacy. So when the developer trains the model, she pays special attention to the "medical bills" document type. What about the other document types? If the model predicts them to be a type they aren't, then the adjustor can verify before they begin to assemble the reimbursement request or contact the customer for more information. She pays similar attention to the extraction part of the process.
- Am I more concerned about false negatives or false positives? In the case of medical bills, we care more about false negatives for both classification and extraction. There could be negative consequences if the model predicts medical bills as belonging to a different document type, or if the model extracts sensitive information thinking it belongs to an insensitive field.
Which metrics should I pay attention to?Copy link to clipboard
Different metrics are suited to help you evaluate model performance based on your use case. The table below outlines which metrics Acme Insurance wants to pay attention to:
| Description | Classification use case | Extraction use case | Metric of interest |
|---|---|---|---|
| Imbalanced data set | The model classifies rental car receipts and towing receipts. Historically, 80% of the total are rental car receipts. | The model extracts data from rental car receipts. Rental car companies include different fields on their receipts. | F-1 score |
| When individual documents are of more interest than the whole document type | The model classifies police reports and towing bills at roughly equal volumes. | Accuracy | |
| When false positives are annoying, but false negatives are detrimental | The model classifies medical bills. It's a bit annoying when the model accidentally classifies a repair estimate as a medical bill, but it's unacceptable when the model misclassifies a medical bill as another document type. | When extracting data from medical bills, it's unacceptable when the model identifies a social security number as a phone number. | Recall |
| When false positive is a major failure and false negative is fine | The model classifies multiple document types, but if it classifies any documents as fraudulent, the case is routed to another department and consumes many resources to investigate. | If the model misidentifies the accident date on the police report, it could be flagged as outside of the claim window and require manual verification to proceed. | Precision |
As you consider these metrics, it's helpful to think about the impact that classification and extraction may have in the context of your process. If a document is classified or a field is extracted incorrectly, what happens next in the process? Does someone have to manually reclassify or identify it? And if so, how much time will that take? Is someone's personal information at risk? Will the process take much more time to fix these issues?
If the answer is yes to these questions, you'll have to evaluate the repercussions against the time savings of integrating AI. A model won't always make correct predictions, so you'll need to determine your appetite for uncertainty or incorrect predictions. The best way to do that is to think of the practical impacts.
Be careful not to overfit the modelCopy link to clipboard
It's tempting to aim for 100% accuracy when training your classification model. Why not try to get every single document classified correctly?
This is a natural goal, but it's misguided. The model is trained on a data set of sample files that represent the files it will encounter in production. By nature, the data set is a selection of the whole, and therefore can never be completely representative.
Overfitting is when a developer trains the model too specifically on the training data set. An overfitted model is very good at classifying the files that were used to train it. However, in production, the model is looking for these specific characteristics or patterns to the exclusion of others – so it misses some files because they don't fit within the model's narrow understanding of the document or email types.
Rather than trying to reach 100% accuracy, we recommend instead using the model in a test environment to see how it performs in the context of your process model.
How to improveCopy link to clipboard
If the model's training results don't yet meet your requirements, you can train another model using additional samples. The more documents, emails, or labels you have, the better.
You'll want to provide a comprehensive set of data to help train the model. Learn how to build a comprehensive machine learning data set.
Continue trainingCopy link to clipboard
As with skills like programming, swimming, or photography, the AI skill will need to regularly refresh its knowledge and understanding of your document types. This can occur if:
- you've gathered more training data
- application requirements have changed to support more or fewer document types or labels
- the model's accuracy has declined in production
These are all occasions when you should consider training the model further to improve it performance for your purposes.