
This page contains definitions for terms used when talking about artificial intelligence and machine learning. Use it as a reference as you learn, build, and fine-tune how to use AI in Appian.
ACopy link to clipboard
AccuracyCopy link to clipboard
Accuracy is the ratio of correct predictions to total predictions, expressed as a percentage. It is a broader metric than precision and recall and may give you more general insight into how your model is performing.
Accuracy is calculated as:
True positives + True negatives
divided by
True positives + true negatives + false positives + false negatives
Learn more about when accuracy is a useful metric in evaluating model performance.
Actual typeCopy link to clipboard
In document or email classification AI skills, the actual type is the document or email's type in reality.
When you create a model, you configure document or email types according to the categories you want to classify, such as invoices or purchase orders. Then, you'll upload documents or emails that represent each type, such as example invoices you've received in the past. Because you upload samples of the type of document or emails you want to classify, the model knows that this is the actual type as it uses them for training and testing.
In production, the actual type determines if the model's guess (predicted type) was correct or not.
For example, if the model predicted a document is invoice but the actual type is a purchase order, the prediction is incorrect.
AlgorithmCopy link to clipboard
Code-based procedures designed to solve a specific problem. In artificial intelligence, a model is constructed of one or multiple algorithms that can be used together to serve a specific purpose.
Appian AI CopilotCopy link to clipboard
Appian AI Copilot is an assistant within Appian that leverages generative AI to help developers or users accomplish tasks more quickly. AI Copilot gives the developer or user a head start, but it doesn’t accomplish tasks independently. Instead, AI Copilot is just that — a copilot. You and your users remain in control. For example, AI Copilot can help create interfaces more quickly by analyzing a PDF that the developer uploads. Additionally, AI Copilot can help end users gain real-time insights about their data in the self-service analytics reports.
Artificial intelligenceCopy link to clipboard
Artificial intelligence (AI) is a computer's capacity for intelligence that mimics a human's or animal's. In other words, AI is a computer's ability to perform tasks and higher order reasoning beyond what it's explicitly programmed to do. It uses machine learning to improve this capacity.
CCopy link to clipboard
CheckboxCopy link to clipboard
A user interface component that allows a user to make a binary choice, often "yes" or "no."
In the context of document extraction, this information is extracted as a label and the selection is saved as a Boolean (true for checked and false for unchecked).
ClassificationCopy link to clipboard
Classification is the process of identifying a document or email type based on certain traits, and assigning it to a group accordingly. In Appian, you can integrate classification into your processes using the document classification or email classification AI skills.
Confidence scoreCopy link to clipboard
A measure of how sure an ML model is of its predictions. When classifying documents or emails in Appian, the model returns a confidence score for each prediction it makes.
Confidence thresholdCopy link to clipboard
A user-determined value to determine if Appian is confident enough in a classification prediction. If the prediction confidence score is below the threshold, for example 90%, a user could design a process to assign a task for a human to perform the review manually.
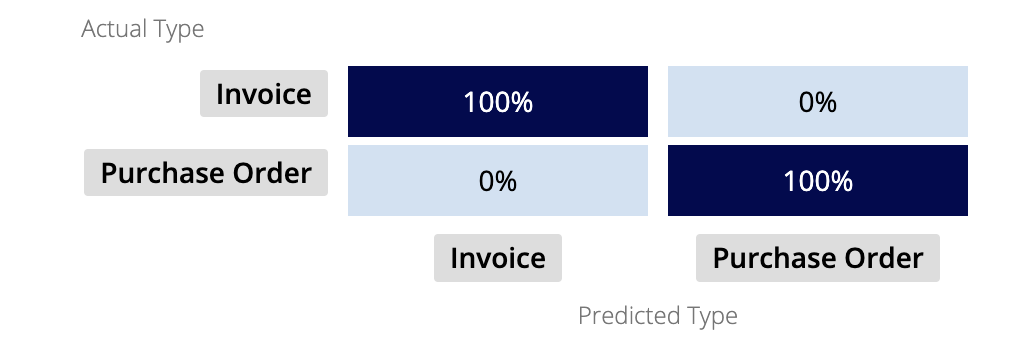
Confusion matrixCopy link to clipboard
A confusion matrix visually represents how the model performed in terms of predicted types vs. actual types.
The confusion matrix grows larger based on the number of document or email types within the model. Because the confusion matrix plots the predicted types against the actual types, you want to see high values on the diagonal cells. Higher numbers in the diagonal indicate that the predicted type matches the actual type, and the model is correctly classifying documents or emails.
DCopy link to clipboard
Data setCopy link to clipboard
The collection of information a developer sends to a model as a basis for training. In the case of document or email classification, the data set is a collection of documents or emails that represent those the model would expect to encounter in production.
Document structureCopy link to clipboard
In the context of document extraction, structure describes how the content in a document is organized. Appian's document extraction features are more effective on certain structures than others. Document structures include: structured, semi-structured, and unstructured.
Document typeCopy link to clipboard
A category of document you use in your business operations. For example, a purchase order or invoice.
Not to be confused with the file type or extension, such as .pdf or .xlsx.
Document extractionCopy link to clipboard
The process of identifying data relationships in a PDF document and digitally representing that information. Appian may use built-in capabilities to extract this information. The process of extraction can also include a user reconciliation task. After reconciliation, Appian will store and recall the mapping of the extracted key to an Appian field.
ECopy link to clipboard
ExtractionCopy link to clipboard
See Document extraction.
FCopy link to clipboard
F-1 ScoreCopy link to clipboard
A metric used to measure accuracy in machine learning. The F-score (aka F1-score) is a quick way to understand the model's ability to fulfill its purpose and make correct predictions. It is computed using precision and recall.
False positiveCopy link to clipboard
When a model incorrectly predicts that a trait of interest is present in the data.
For example, a model is trained to predict either stop signs or cars in images it analyzes. The model analyzes an image and predicts it contains a car, but the image actually contains a stop sign. This prediction is a false positive with respect to the car class, and a false negative with regards to the stop sign.
False negativeCopy link to clipboard
When a model incorrectly predicts that a trait of interest is not present in the data, but it is.
For example, a model is trained to predict either stop signs or cars in images it analyzes. The model analyzes an image and predicts it contains a car, but the image actually contains a stop sign. This prediction is a false positive with respect to the car class, and a false negative with regards to the stop sign.
FieldCopy link to clipboard
A single piece of data to be extracted from a document.
FieldCopy link to clipboard
A single piece of data to be extracted from a document and mapped to a data type.
Fillable PDFCopy link to clipboard
Similar to a searchable PDF, this file allows the user to input and save additional information into form fields.
Flattened PDFCopy link to clipboard
A PDF with no text data associated with the file. It doesn't contain digital text or form fields. Often, these types of PDFs are created from paper documents that have been scanned.
KCopy link to clipboard
KeyCopy link to clipboard
See label.
Key-value pairCopy link to clipboard
A match between two data elements (a label and value) that are extracted from a document.
LCopy link to clipboard
LabelCopy link to clipboard
The extracted constant that defines a part of a data set. This information isn't changed based on the user's selection or input. It is matched with the value to create a key-value pair in the extracted data. For example, "Name" is a label, and "John Smith" is a value.
When used as a verb, label is the act of identifying these constant values in a document where extraction will be performed. When you configure a document extraction AI skill, you'll label a sample document to identify these values for model training. For example, when you click "Name" on a document, you label that field.
MCopy link to clipboard
Machine learningCopy link to clipboard
The pursuit and practice of building software that seeks to improve its artificial intelligence independently. Machine learning (ML) enables computers to learn from experience and improve future performance without being programmed to do so.
ModelCopy link to clipboard
A model is the product of combining a data set with a machine learning algorithm. A model is unique to a purpose which requires recognition, understanding, reasoning, and decision-making. For example, the model used to classify purchase orders isn't necessarily the same one that can recognize stop signs in a set of pictures.
MappingCopy link to clipboard
The act of matching data extracted from a field in a document to a field in a CDT.
ModelCopy link to clipboard
A model is the product of combining a data set with a machine learning algorithm. A model is unique to a purpose which requires recognition, understanding, reasoning, and decision-making. For example, the model used to classify purchase orders isn't necessarily the same one that can recognize stop signs in a set of pictures.
OCopy link to clipboard
Optical character recognition (OCR)Copy link to clipboard
OCR software recognizes text within a digital image. This technology is well-suited for unstructured documents, but it is less accurate and requires more maintenance than purpose-built document extraction models.
OverfittingCopy link to clipboard
Overfitting is when a model is trained too specifically on test data, to the point that it looks for very specific patterns and can't detect patterns in real data.
For example, imagine you are training a model with a data set that contains 100 invoices. These invoices are examples of ones your business has received in the past. If you train the model too much on this data set (trying to reach 100% accuracy), it's possible that the model won't be able to adapt and detect invoices that look differently in production than the invoices in your test data set.
OutcomesCopy link to clipboard
The four categories the model's predictions can fall into, when compared to reality:
| Term | Prediction | Reality |
|---|---|---|
| True positive | Image contains a stop sign | Image contains a stop sign |
| True negative | Image doesn't contain a stop sign | Image doesn't contain a stop sign |
| False positive | Image contains a stop sign | Image doesn't contain a stop sign |
| False negative | Image doesn't contain a stop sign | Image contains a stop sign |
PCopy link to clipboard
PrecisionCopy link to clipboard
Precision is expressed as a value between 0 and 1, which indicates the number of true positive predictions the model made, compared to the total number of positive identifications (including those that are false). In other words, it answers the question: out of all of the positive guesses, how many were correct?
For example, a model is given 10 documents and tasked with identifying how many of them are invoices. There are 4 invoices in the set of documents, but the model positively identifies only 3. However, those 3 identifications are correct (true positives). In this example, the model's precision is 1.0 because all of its predictions were correct (no false positives), even though it didn't identify all of the invoices.
Precision is closely related to recall, and together they calculate the F-1 Score.
Precision is calculated as:
divided by
True positives + false positives
Learn more about when precision is a useful metric in evaluating model performance.
Positional extractionCopy link to clipboard
Ability to extract data from a document based on its location in a document. Appian can use positional extraction if it has processed the documents and learned from the results previously.
Predicted typeCopy link to clipboard
In document classification AI skills, the predicted type is the output of the model's analysis of a document. The model attempts to classify documents based on the document types that were used to train the skill.
Simply put, the predicted type is the model's guess when classifying a document. For example, "invoice" or "purchase order." The actual type determines if the model's guess (predicted type) was correct or not.
For example, if the model predicted a document is invoice but the actual type is a purchase order, the prediction is incorrect.\
Private AICopy link to clipboard
Private AI is Appian's approach to protecting your data during model creation, training, and use. Private AI is a set of algorithms that exist only for the customer’s use. The customer controls access to those algorithms, as well as the data used to train them. Private AI is the best and most secure way to integrate AI into your processes.
RCopy link to clipboard
RecallCopy link to clipboard
Recall is the number of actual correct predictions a model made. Unlike precision, recall also considers the number of correct predictions the model didn't make. It answers the question: out of all of the guesses, how many were correct positive predictions?
For example, a model is given 10 documents and tasked with identifying how many of them are invoices. There are 4 invoices in the set of documents, but the model identifies only 3. However, those 3 identifications are correct (true positives). It missed identifying 1 invoice (false negative). In this example, the model's recall is .75 because it missed predicting one of the invoices.
Recall is closely related to precision, and together they calculate the F-1 Score.
Recall is calculated as:
divided by
True positives + false negatives
Learn more about when recall is a useful metric in evaluating model performance.
ReconciliationCopy link to clipboard
The manual task of confirming or updating data Appian extracted from a document. Functionally, users compare the data that was extracted to an image of the uploaded document. When reconciliation occurs, Appian learns how to map the data in documents to the proper fields in the corresponding data type. Over time, this will make auto-extraction more accurate and reconciliation easier and less frequent.
SCopy link to clipboard
Searchable PDFCopy link to clipboard
A PDF that contains digital text data that can be highlighted, copied, searched, and accessed programmatically. This type of PDF has undergone previous processing or was saved from a word processor.
Semi-structured documentCopy link to clipboard
Documents that include similar pieces of information, but in varying layouts. Invoices, receipts, and utility bills are good examples of documents with semi-structured data. Appian's document extraction features are well equipped to identify and extract semi-structured data. Through AI and machine learning, the services improve as you process additional documents.
Straight-through processingCopy link to clipboard
Straight-through processing occurs when Appian is able to extract document data that is 100% accurate, eliminating the need for a reconciliation task.
Structured documentCopy link to clipboard
Documents containing information that is arranged in a fixed layout. Tax forms, passport applications, and hospital forms are good examples of documents with structured data. Appian can extract data from these types of documents easily due to the predictable and consistent positions of labels and values.
TCopy link to clipboard
TableCopy link to clipboard
Information displayed in a grid-like format, often using columns and rows to show similar information in a predictable way.
In document extraction, a table is a subset of the overall document data and requires additional configuration to extract and store the data properly.
TrainCopy link to clipboard
Training is the process by which an ML model learns and improves. In the context of a developer workflow, training also means the repetition of providing more data to the model, so that it gets better at predicting or classifying that information.
True positiveCopy link to clipboard
When a model correctly predicts that a trait of interest is present in the data. For example, if the model predicts that an image contains a stop sign, and it actually does, this prediction would be categorized as a true positive.
True negativeCopy link to clipboard
When a model correctly predicts that a trait of interest is not present in the data. For example, if the model predicts that an image doesn't contain a stop sign, and it doesn't, this prediction would be categorized as a true negative.
TypeCopy link to clipboard
See Document type.
UCopy link to clipboard
Unstructured documentCopy link to clipboard
Documents that include free-flowing paragraphs of text. Legal contracts and emails often include unstructured data. This type of information is more difficult to extract because the machine learning algorithms that identify the information are looking for key-value pairs. Larger blocks of text, or parts of that text, are more difficult to extract.
VCopy link to clipboard
ValueCopy link to clipboard
The extracted variable that defines a part of a data set. This information is changed based on the user's selection or input. It is matched with the label to create a key-value pair in the extracted data. For example, "Name" is a label, and "John Smith" is a value.