
| The capabilities described on this page are included in Appian's advanced and premium capability tiers. Usage limits may apply. AI Skill is only available for Cloud customers at this time. Self-managed and Appian GovCloud customers don't have access to this feature. Appian Cloud HIPAA or PCI-DSS customers: Before enabling this feature, please review its compliance to ensure it aligns with your organization's security requirements. |
This topic covers how to create an AI skill to extract text from documents using machine learning (ML) models.
What is an AI skill?Copy link to clipboard
An AI skill is a design object that enables you to build, configure, and train an ML model using low-code. A Document Extraction skill takes a document as input via the Extract from Document smart service, analyzes the document, and returns a map of the text extracted from the document.
Tip: You'll create a document extraction AI skill for each type of document you want to extract data from.
Here's a high-level breakdown of how to create and use a document extraction AI skill:
- Create an AI skill
- Define the document structure
- Map extracted data to process variables
- Use the skill!
Create an AI skillCopy link to clipboard
Note: This AI skill type is only available in select regions.
-
In the Build view, click NEW > AI Skill.
-
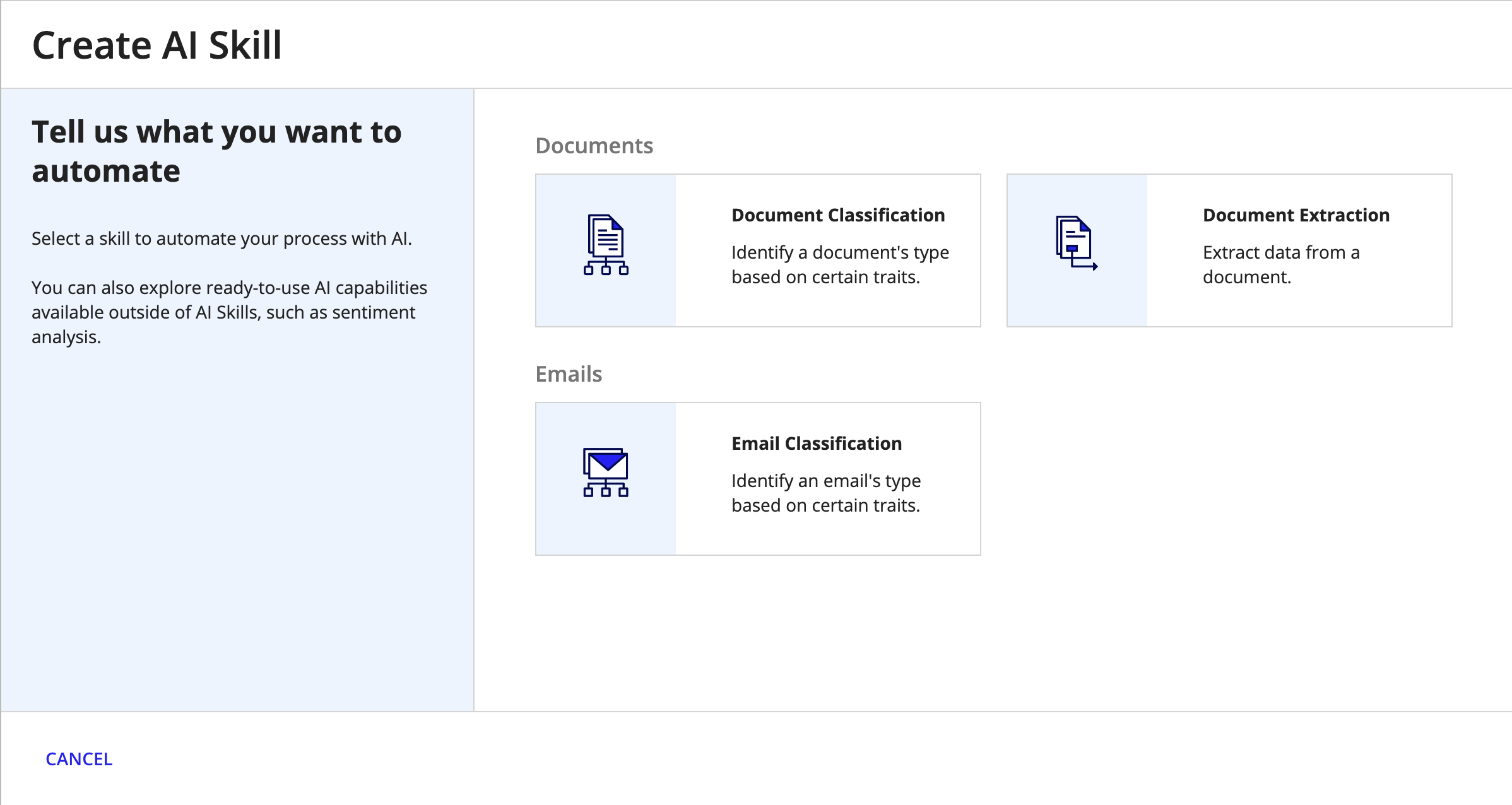
Select the skill type you want to create.
-
Configure the following properties:
Property Description Name Enter a name that follows the recommended naming standard. Description (Optional) Enter a brief description of the AI skill. - Click CREATE.
- On the Review AI Skill Security window, configure security.
- Click SAVE. The AI skill opens in a new dialog or window.
Next, you can define the document structure.
Define the document structureCopy link to clipboard
The document extraction AI skill is powered by a machine learning model designed to extract data from structured and semi-structured forms. The skill can be useful for documents businesses commonly receive, such as invoices or purchase orders.
To get started, you'll add the fields that commonly appear in the document type. For example, if you're building an AI skill to extract data from invoices, you'll want to add common fields that contain the data you want to extract, such as Invoice Number, Date, and Vendor Name.
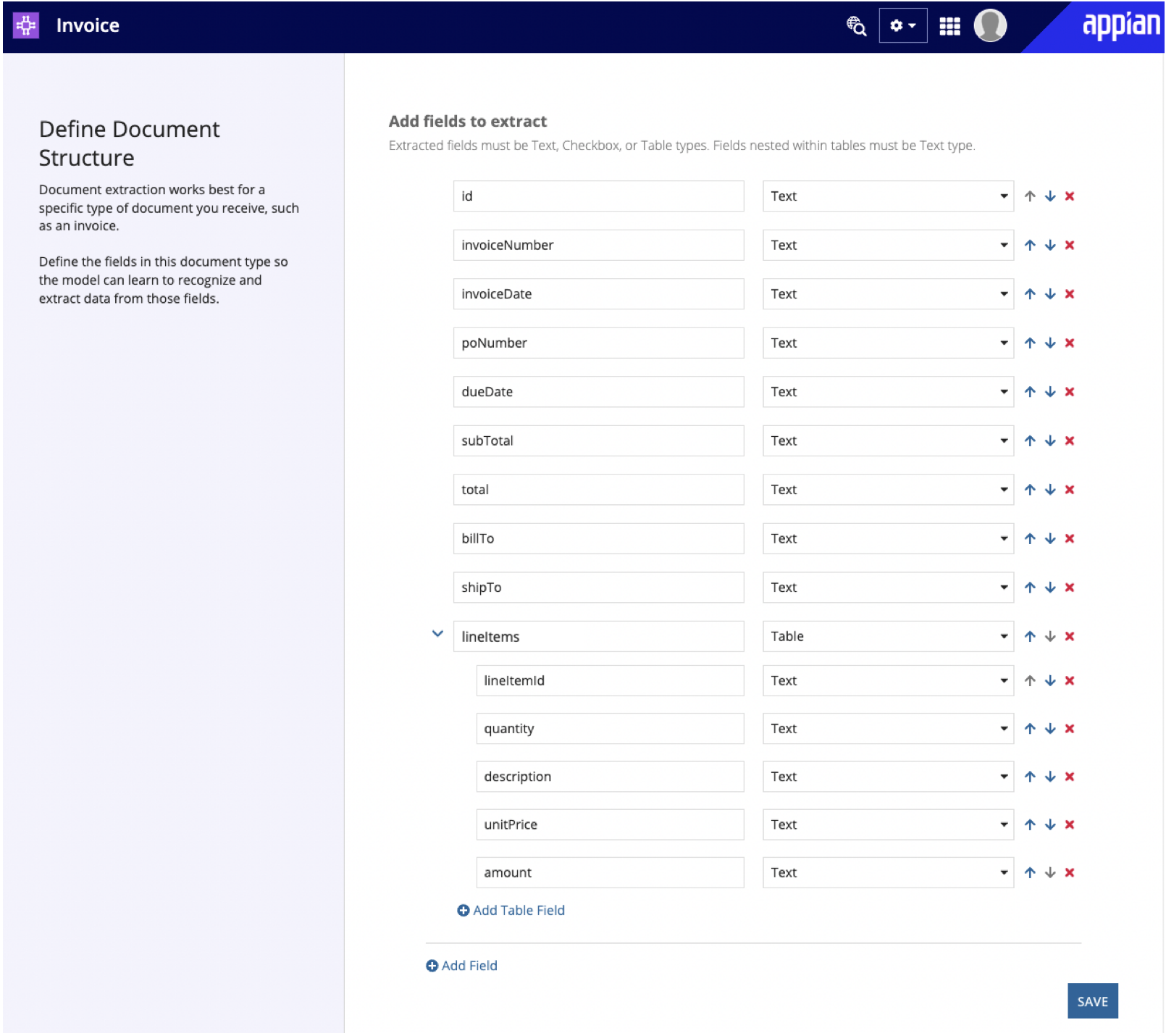

Before Appian can extract data from your documents, you'll need to define what those fields are and the type of data they contain:
- On the Define Document Structure page, enter a field name. If you plan to save extracted data to a record type or CDT, see field naming guidelines below.
- Choose the data type for this field. Extracted fields must be Text, Checkbox, or Table types. Fields nested within tables must be Text type.
- Click Add Field to add more fields.
- Continue to add field names and data types until you've defined all of the fields you want to extract from this document type.
Tip: Add a field for each piece of data in the document you want to extract using the AI skill. If you don't add a field, the skill won't know to extract the data or how to label it.
Mapping extracted dataCopy link to clipboard
The document extraction AI skill extracts data as type Text or Boolean (for checkboxes). However, your document data may be of different data types, such as Dates or Numbers. Additionally, you may want to save this extracted data in specific data objects, such as record types or custom data types (CDTs).
To ensure your data reaches the intended destination and in the proper format, you'll need to properly name and map fields as you configure your AI skill and smart service.
Mapping data as you define the document structureCopy link to clipboard
Pick the right name for the field as you define your document structure in the AI skill.
Flat data: If you're planning to save extracted data to a flat CDT or record type, name each field in the document structure to match the target field so Appian casts it properly.
- Example: You want to extract data from invoices. Each invoice has a field containing the name of the vendor. You want to configure your process so that the smart service saves this value into the
invoiceNumberfield in yourInvoicesReceivablerecord type. To achieve this, create ainvoiceNumberfield (type: Text) in your skill to match its ultimate destination (theinvoiceNumberfield in your record type) in Appian.
Tables (nested data): If you plan to extract document data that's formatted in a table, you'll need to carefully name these fields as well. When Appian extracts data from a table in a document, the results is a list of maps, with each map representing a row in the table. The name you choose for the table field helps Appian cast all of this data properly.
Name the table fields based on the data object where you plan to store it:
- Record type relationships: name the field to match the Relationship Name.
- CDTs: name the field to match the field name you assigned the table CDT in the parent CDT. Learn more about creating CDTs to store extracted document data.
Example: You want to extract data from invoices. Each invoice has a table containing a list of items you ordered, the unit costs, and how many of each item you ordered. Invoice data is stored in the Invoice CDT, which contains a field lineItems (type: Invoice_Table CDT) to store itemized data from tables in each invoice. You want to configure your process so that the smart service saves the itemized values into the Invoice_Table CDT.
To achieve this, create a lineItems (type: Table) field in your skill to match its ultimate destination (the Invoice_Table CDT, by way of the lineItems field of the Invoice CDT) in Appian. Additionally, name each field within the table to match the corresponding fields within the CDT as well.
The following image include numbers to demonstrate the fields that should match when extracting table data with an AI skill.
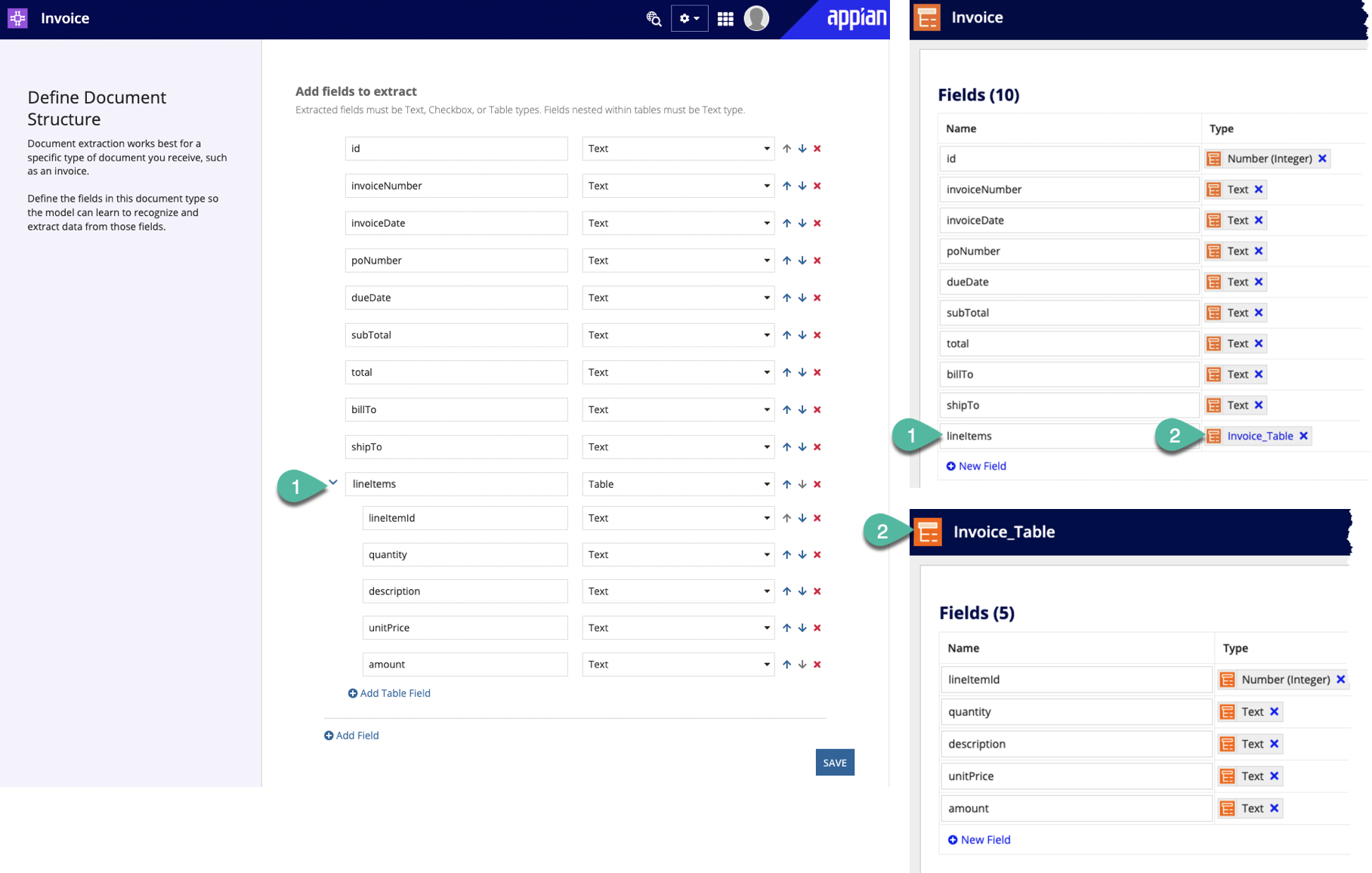
The following table summarizes guidance for naming fields in your document structure:
| Extracted data type | Target location | Field name requirement | Example field name |
|---|---|---|---|
| Text or Boolean | Record type or CDT | Field name must match the target field. | invoiceNumber |
| Table | Record type relationship | Field name must match the name of the relationship. | maInvoiceItems |
| Table | CDT | Field name must match the name of the field that contains table data. Fields within the table must match the names of the fields within the CDT. | lineItems |
Mapping data as you configure the processCopy link to clipboard
As you build your process, you'll map the smart service output to process variables. Appian supports casting data from Maps to CDTs or record types so you can use the extraction results to write to your database.
Note: Review the design guidance to ensure that the fields in your AI skill are named based on how you want to cast the data.
To ensure that the AI skill extracts and uses your data as you intend, carefully map the Extract from Document smart service output to the proper variables so your data is used or stored properly:
- Double-click the Extract from Document smart service node.
- Go to the Data tab.
- Go to the Outputs tab.
- In the Results section of the outputs tree, click Extracted Data. The results properties display in the right pane.
- In the Target field, select the process variable you want to use to store this data, including Record Types or CDTs.
Use the skillCopy link to clipboard
Now you're ready to use your document extraction skill in a process.
Add the Extract from Document smart service and configure it to call your new skill. You'll also want to add the Reconcile Doc Extraction smart service so a person can verify that the extracted data maps to the proper fields.
Tip: The Extract from Document and Reconcile Doc Extraction smart services include the Is Structured Doc input. Set this value to true when extracting fields that are in the same location for all documents. Is Structured Doc allows Appian to learn about this data using its location, thereby making future extractions more accurate.
How does document extraction work in Appian?Copy link to clipboard
There are multiple ways to integrate document extraction into an Appian process. No matter the method you use, you may be curious how it works. This section provides more detail on how Appian extracts and maps data from your documents.
First, it's important to remember that Appian document extraction is powered by pre-trained machine learning (ML) models, allowing you to get started quickly. When you extract document data in Appian, you aren't creating a model or training one on data you provide. Instead, Appian learns about your data via reconciliation tasks. Appian applies this learning in subsequent extractions of the same document type, but the model is not retrained.
The document extraction process – either within the Extract from Document or Start Doc Extraction smart services – consists of three parts:
- Extract data from a PDF using a pre-trained ML model.
- Map the extracted data to the customer's Appian data structure for reconciliation.
- Complete a reconciliation task to verify the mapped data is correct.
Tip: See the Document Extraction glossary for a refresher on the terms used on this page.
Step 1: Data extractionCopy link to clipboard
Who: Appian
Input: PDF
Output: Identified text, key-value pairs, checkboxes, and tables
In the first step, the PDF goes to a pre-trained ML model to run optical character recognition (OCR), extract key-value pairs, and identify special document formatting checkboxes and tables. The model returns all identified values (represented by blue bounding boxes in the image below). Keys are represented by purple bounding boxes for reference, but they do not appear in Appian.

Step 2: Data mappingCopy link to clipboard
Who: Appian
Input: Identified text, key-value pairs, checkboxes, and tables from step 1
Output: Reconciliation user input task
Next, Appian leverages previous mappings stored in the customer's environment to know which extracted data to map to the document structure. These mappings are stored in a dictionary as you complete reconciliation tasks over time (step 3). So, the more mappings and reconciliation tasks you complete for a given document type, the better Appian is at mapping that data. Each subsequent reconciliation task is faster and more accurate.
If your Appian environment has previously mapped values to your structured fields, Appian leverages those previous keys to assist in mapping the data before assigning a reconciliation task.
Example

In the image above, Appian extracted Invoice# as the key and INV-12 as the value in this document. In the document structure, there is a field named invoiceNumber. Invoice# and invoiceNumber don't match, but that's okay! If you previously mapped the Invoice# key to the invoiceNumber field in a reconciliation task, Appian should automatically map this data for you.
Each time a user completes a reconciliation task, Appian stores updated mappings in a simple dictionary of terms (keys and positions) to use next time it has to map data from the pre-trained model (output of step 1) to the structured fields in your application.
Step 3: ReconciliationCopy link to clipboard
Who: User
Input: Identified and mapped text, key-value pairs, checkboxes, and tables from step 2
Output: Auto-extracted fields to Appian process model for use in your application
Finally, a user completes a reconciliation task to confirm that the mappings from step 2 are correct. When a user maps data to a field and submits the reconciliation task, Appian stores the label for the key that was mapped. For example, if you provide mappings, Appian will recognize that P.O. #, and PO No. both map to the poNumber Appian data type field.
Reconciliation helps Appian manage variations in semi-structured and structured forms. In this way, reconciliation helps document extraction learn more about your data.
As you complete reconciliation tasks, data mapping in step 2 improves because Appian can match the keys to more options. However, the model in step 1 does not get retrained when you submit a reconciliation task with updated mapping. This means that if the ML model misses a field in step 1, Appian will continue to miss that field in step 2, and that there are some forms where auto-extraction will not extract the data desired. In these situations, customers can use manual extraction in step 3 to get the last pieces of information.