
OverviewCopy link to clipboard
One of the most common uses for custom data types (CDTs) is for reading from and writing to a database table or view. CDTs are connected to the database through data stores. The CDT defines the data structure within Appian and how it maps to the database table, while the data store defines how Appian connects with the database.
If you have an existing database table or view that you need to connect to or you have specific guidelines that prohibit Appian from modifying your database, you can create and update your CDT as described on this page.
If instead you have a CDT but want Appian to generate a table for you in the database, see the Generating Database Tables from CDTs page.
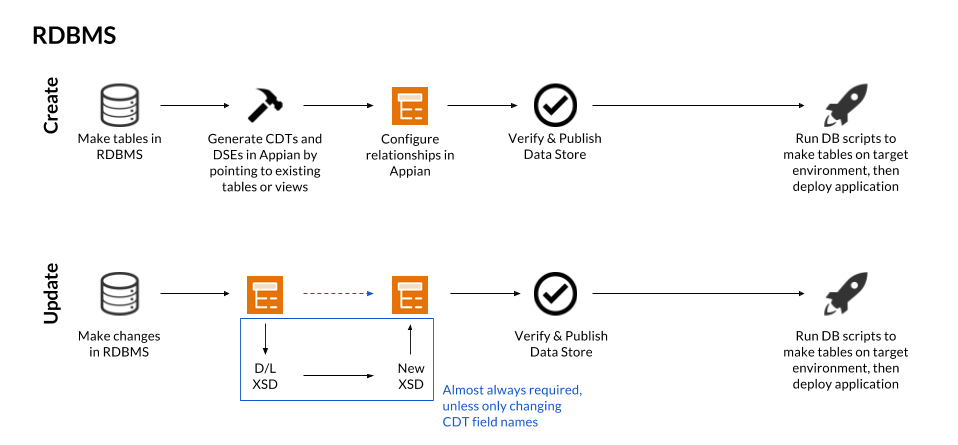
CreateCopy link to clipboard
To create a new CDT based off a particular database table or view:
- In your application, go to the Build view.
- Click NEW > Data Type.
- Select the Create from database table or view option.
- For Data Source, select a database. If you don't see the correct database, contact a system administrator to configure the relational database.
-
If the selected data source is a SQL Server, PostgreSQL, or DB2 database, use the Schema dropdown to select a schema. The schema will be pre-populated for Oracle databases and cannot be changed.
Note: If your database schema contains synonyms that expose tables or views from a different schema, those tables and views will not be available in the Table or View dropdown. You can still map CDTs to synonyms, but CDTs cannot be created automatically based on a synonym.
You can create CDTs based on the table or view that the synonym points to by selecting the schema in which those tables or views live from the Schema dropdown.
- For Table or View, select the table or view for which you want to create a CDT.
- Click Continue.
-
Review the CDT and make any necessary modifications:
- Edit the name and description of the CDT.
- Define or update the primary key.
- Review the fields created for each column in the table or view. If a field is missing, it may be because the database column type is not supported. See the field types section for a list of supported column types and how they map to Appian types.
- Select or create a data store entity to allow Appian to read and write to the table or view.
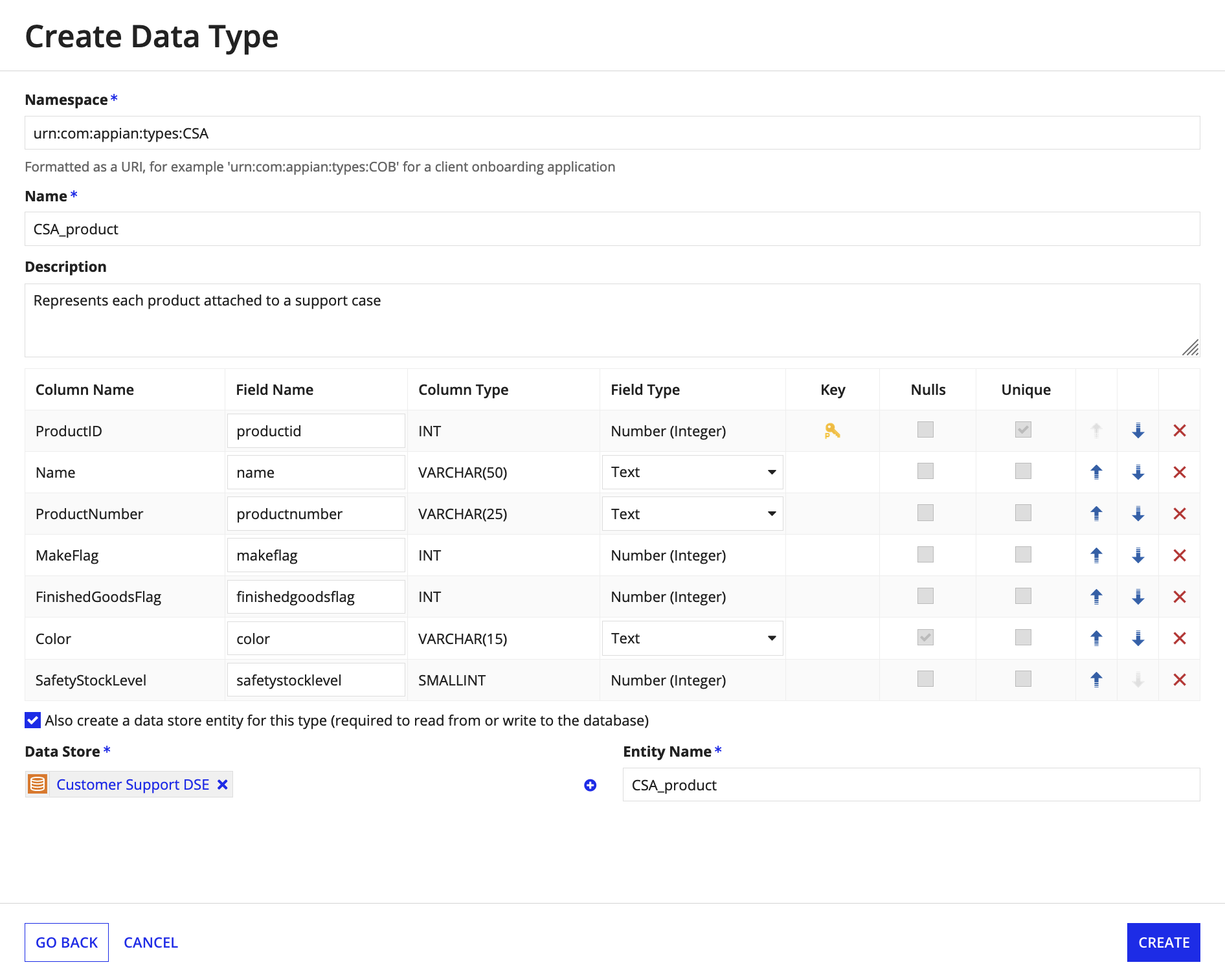
- Click Create.
Primary keysCopy link to clipboard
All data types that map to a database table or view must have a primary key defined. Without a primary key, the data store will fail to publish and Appian will offer to generate one for you.
We do not recommend allowing Appian to generate the primary key column because it cannot be queried or referenced by processes, so it is impossible to update any existing value in the database table. Additionally, your data type must have an explicit primary key field in order to be used as the source for a record type.
Creating a CDT based on a database table or view handles primary keys in the following ways:
- If the database table contains a single primary key, that will be automatically set on your CDT.
- If the database table does not contain a primary key or you create a CDT based on a view, you will have the option to set the primary key by clicking on the key icon for that field.
- If the CDT is based on a view, you must use a unique field for the primary key. Appian uses the primary key to query the data store. If the key is not unique, queries may return inconsistent responses, and any Excel or CSV exports of the data may be incomplete.
- If the database table contains multiple primary keys, your data store will not publish and you cannot connect to the table. You will have the opportunity to remove additional primary keys or select another column as the primary key. Appian recommends that you choose only one column as the primary key. See Database Schema Best Practices: Composite Keys for more information on how to work with tables with composite keys.
Primary key values can be either explicitly set or autogenerated by the database. This will determine the behavior when you are attempting to write values to the database:
- If the value is autogenerated, writing a CDT value with a null primary key will create a new row in the table and assign a value.
- If the value is not autogenerated, writing a CDT with a null primary key will fail.
If your database table contains a primary key that is autogenerated, that will be automatically set on your CDT for most databases. In Oracle, however, you need to specify what sequence will be used to generate the value. Therefore, when creating a CDT based on an Oracle table, you will see a warning message that indicates you need to select a sequence.
Note: The increment value of the autogenerated sequence can only be set to 1 for your database table. Any increment value greater than 1 is not supported.
To select a sequence:
- Click on the primary key icon for the field that is autogenerated. This launches the Configure Primary Key Constraint dialog.

- Select the Auto-generate the next unique identifier when new records are written to a data store entity checkbox.
- Select the Sequence that your database table should use. The sequences are filtered by schema, which defaults to the schema that your table is in. The name of the sequence will typically be very similar to the table name, such as
TABLENAME_SQ. - Click OK.
Create a data store entityCopy link to clipboard
Data store entities are required in order to read from or write to a database table or view. When you create a CDT from a database table or view, you can choose to have a new entity automatically created for you.

From here, you can select an existing data store or create a new one. A new entity with the specified name will be added to that data store when you create the data type.
If you chose to create a new data store, the data store will automatically be added to your application and you will be prompted to set its security. See Data Store Security for additional information on the security role maps of data stores.
ResultsCopy link to clipboard
After you create a CDT, an XML Schema Definition (XSD) file that corresponds to your CDT is also created. The following sections explain the different aspects of the file.
Field typesCopy link to clipboard
The table below lists the supported database column types and their corresponding Appian data types. Any aliases of the database column types also map to the listed Appian types.
Note: This set of supported database column types is based on the recommended drivers for the last version of each of the supported databases. If you are using different drivers or are using an older version of the database, the list of supported columns may differ slightly.
| Appian Type | MySQL/MariaDB Type(s) | MS SQL Server Type(s) | Oracle Type(s) | PostgreSQL Type(s) | DB2 Type(s) |
|---|---|---|---|---|---|
| Text | VARCHAR ENUM SET CHAR BINARY VARBINARY TEXT LONGTEXT |
VARCHAR NVARCHAR SYSNAME CHAR UNIQUEIDENTIFIER BINARY TIMESTAMP XML NTEXT NCHAR VARBINARY TEXT |
VARCHAR VARCHAR2 CHAR RAW BLOB UROWID BFILE CLOB XMLTYPE |
BYTEA CHAR VARCHAR TEXT |
VARCHAR VARGRAPHIC CHAR GRAPHIC |
| Encrypted Text | VARCHAR ENUM SET CHAR BINARY VARBINARY TEXT LONGTEXT |
VARCHAR NVARCHAR SYSNAME CHAR UNIQUEIDENTIFIER BINARY TIMESTAMP XML NTEXT NCHAR VARBINARY TEXT |
VARCHAR VARCHAR2 CHAR RAW BLOB UROWID BFILE CLOB XMLTYPE |
BYTEA CHAR VARCHAR TEXT |
VARCHAR VARGRAPHIC CHAR GRAPHIC |
| Number (Integer) | INTEGER INTEGER UNSIGNED INT INT UNSIGNED BIGINT BIGINT UNSIGNED MEDIUMINT MEDIUMINT UNSIGNED SMALLINT SMALLINT UNSIGNED TINYINT TINYINT UNSIGNED |
INT INT IDENTITY SMALLINT SMALLINT IDENTITY TINYINT TINYINT IDENTITY |
NUMBER SMALLINT INT |
INT2 INT4 INT8 SERIAL2 SERIAL4 SERIAL8 |
INTEGER SMALLINT |
| Number (Decimal) | DOUBLE DOUBLE PRECISION REAL NUMERIC FLOAT DECIMAL SMALLINT UNSIGNED TINYINT TINYINT UNSIGNED |
FLOAT NUMERIC NUMERIC IDENTITY REAL BIGINT BIGINT IDENTITY DECIMAL DECIMAL IDENTITY MONEY SMALLMONEY |
REAL FLOAT DOUBLE |
FLOAT4 FLOAT8 MONEY NUMERIC |
DOUBLE REAL BIGINT DECIMAL |
| Boolean | BIT BOOL |
BIT | BIT BOOL |
BOOLEAN | |
| Date | DATE | DATE | DATE | DATE | |
| Time | TIME | TIME | TIME TIMETZ |
TIME | |
| Date and Time | DATETIME TIMESTAMP |
DATETIME DATETIME2 SMALLDATETIME DATETIMEOFFSET |
DATE TIMESTAMP TIMESTAMP WITH TIMEZONE |
TIMESTAMP TIMESTAMPTZ |
TIMESTAMP |
If your database table contains a column type that is not listed in the table above, that column will not be included in your CDT. You may still be able to manually map a field in your CDT to that column, but it is not guaranteed to work correctly.
For example, if your database column is of type BLOB, it will not be included in your CDT because Appian typically cannot support that size of data in a single field. However, if you are not using the BLOB field for its intended usage, you may be able to safely store text in a field of type BLOB in Appian, so Appian does not prevent you from adding a field that maps to that column and uploading a new version of the XSD file.
AnnotationsCopy link to clipboard
JPA annotations are used to map CDTs to existing database tables or views. The following JPA annotations may be used when creating a CDT from a database table or view.
| Annotation | Description | When It's Used |
|---|---|---|
| @Table | Defines what table or view the CDT will map to when publishing a data store | All CDTs |
| @Column | Defines what column in the table or view the field corresponds to as well as the type of the database column. The column type is specific to the type of database, so this annotation may need to be modified if you need to map this CDT to a table in a different database type. | All fields within the CDT |
| @JoinColumn | Defines what column in the table the field corresponds to, the type of the column, and the foreign key relationship with another table | Any foreign key column in the CDT |
| @Id | Defines the primary key field | When defined |
| @GeneratedValue | Specifies that the database will automatically generate the value for a primary key | When defined |
| @SequenceGenerator | Specifies what sequence will be used to automatically generate the primary key value. Only applicable to Oracle tables. | When defined |
To successfully map to the database table, you only need the annotations that are automatically added to your XSD. However, you may want to add additional annotations to specify additional information that cannot be read from the database table. To add additional JPA annotations to your CDT, download and modify the XSD.
RelationshipsCopy link to clipboard
When you create a CDT from a database table, any foreign key relationships that are defined on the table are automatically specified within the CDT using the @JoinColumn annotation. By default, this is a flat relationship, which means you will not be able to reference fields from the other table.
In order to reference those fields, you will need to specify a CDT relationship. CDT relationships are defined in the data type designer after the CDT has been created.
UpdateCopy link to clipboard
The following sections describe how update a CDT.
Remember that each time you update a CDT, all dependent objects are updated automatically to reference the latest version of the data type, including any data stores that are used to connect the CDT to a database. If your data store verifies, the data store will be published automatically. If it does not verify, the database table will only be updated if you have Automatically Update Database Schema enabled. See Data Stores for more information.
Before updating any data type, be sure you understand the impact it will have on objects that reference that data type, including running processes.
Add new fieldsCopy link to clipboard
If your database table contains columns that are not in your CDT and you would like to add them to the CDT, you should add the new field directly in your XSD. To do this, download the XSD, add the new fields, and upload the new version to update the CDT.
When adding the new field, be sure to include the @Column annotation to specify the name and type of the column that the field maps to, as shown in the example below:
1
2
3
4
5
<xsd:element name="customername" nillable="true" type="xsd:string">
<xsd:annotation>
<xsd:appinfo source="appian.jpa">@Column(name="customerName", columnDefinition="VARCHAR(255)")</xsd:appinfo>
</xsd:annotation>
</xsd:element>
Copy
Typically, you can just copy the <xsd:element> block from a previous field and change the relevant information. If you don't have any other fields of that type, you can reference the default XSD types section for guidance on what XSD type to use.
Update existing fieldsCopy link to clipboard
The following sections tell you how to update each of the field's attributes.
Name or typeCopy link to clipboard
If you've updated the name or type of a column in your database and need to update your CDT field to match, you can download the XSD, modify the name or columnDefinition attributes in the @Column annotation for that field, and upload the new version. This change will take effect immediately upon saving the CDT.
If you need to change the name or type of the field within the CDT but are not changing the corresponding column, you can make those changes directly in the data type designer. Your @Column annotation in your CDT will not be modified when you make a change through the data type designer, so your field will continue to map to the database column as it did before. However, remember that if you're changing the field type to something that won't translate well to your database column type, you may need to also update the column itself and the corresponding @Column annotation in the XSD.
Caution: Individual fields within a CDT do not display when viewing the dependents for that CDT, so there is no way to reliably know what objects are using each field. Therefore, it can be very difficult to correctly update all objects when you change the name or type of a field. Be sure to thoroughly test your changes in order to ensure that you've updated all the appropriate objects.
Additionally, running processes cannot be updated to use the latest version of a CDT. Therefore, changes to a CDT, its underlying database structure, or related artifacts such as rules and subprocesses may cause the running processes to behave unexpectedly.
RelationshipCopy link to clipboard
To update the relationship information for a nested CDT such as the type (parent-child or lookup) or cascade type, you can go to the data type designer and make the change. This change will take effect immediately upon saving the CDT.
Other annotationsCopy link to clipboard
To add or update any other JPA annotations on a CDT field, you can download the XSD, modify the annotations for that field, and upload the new version. Because annotations only take effect for new columns, adding additional annotations to existing fields will not have an effect on any existing columns in your table.
Delete fieldsCopy link to clipboard
You can remove fields from your CDT directly from the data type designer. You do not have to remove the corresponding column from the database; your CDT will no longer have the ability to reference the corresponding column in the database once the field is removed.
Caution: Individual fields within a CDT do not display when viewing the dependents for that CDT, so there is no way to reliably know what objects are using each field. Therefore, it can be very difficult to correctly update all objects when you remove a field. Be sure to thoroughly test your changes in order to ensure that you've updated all the appropriate objects.
Additionally, running processes cannot be updated to use the latest version of a CDT. Therefore, changes to a CDT, its underlying database structure, or related artifacts such as rules and subprocesses may cause the running processes to behave unexpectedly.