
| Process Mining is deprecated with Appian 24.2 and will no longer be available in an upcoming release. Instead, we encourage customers to use Process HQ to explore and analyze business processes and data. |
Estimated time to complete tutorial: about 1 hour
User experience level: Beginner
IntroductionCopy link to clipboard
In this tutorial, you'll use Appian Process Mining to discover insights and optimize an order-to-cash (O2C) process. This process you'll optimize is for a pizza restaurant named Process Dining Pizzeria that's located in New York City. You'll use Mining Prep to transform and load process data from their order processing system. You'll use Process Mining to discover how your process actually runs, and you'll perform root cause analysis on process deviations to identify optimization opportunities.
For this tutorial, you'll be assuming the role of an analyst for Process Dining Pizzeria with the goal of improving the efficiency of their ordering system. Customer service has received complaints about orders taking too long and pizzas arriving un-sliced. Let's see how we can resolve these problems using Appian Process Mining.
System requirementsCopy link to clipboard
This tutorial is designed to be used with:
- Process Mining 5.6 or later.
- Mining Prep 5.6 or later.
Quick definitionsCopy link to clipboard
This tutorial will go more smoothly if you understand these terms, used in the context of Appian Process Mining:
- Event log: A file that represents a process as a sequence of events. This file must include at a minimum a case ID, activity name, and time stamp. Event logs are commonly CSV files.
- Discovered model: A visualization of an actual process based on an event log.
- Target model: A visualization of a target process in the form of a BPMN file.
- Activity: A real-world task or action that occurs as part of a process. The nodes in a discovered model represent activity names. The historical execution of these activities is stored in an event log.
- Event: The digital representation of when an activity occurred. An instance of an activity. A sequence of events that are associated with the same case ID form a case or a single occurrence of a process.
Part 1: SetupCopy link to clipboard
Before you begin, make sure to complete the following steps.
Download required filesCopy link to clipboard
To complete this tutorial, you'll need to download and unzip the following file: Process-Mining-Tutorial.zip. This ZIP file contains:
- Events:
pizza-order-events.csv - Case attributes:
case-attributes.csv - Location key:
location-key.csv - Target model:
target-pizza-order.bpmn
Download and unzip Process-Mining-Tutorial.zip file before you begin the tutorial.
Administrator setupCopy link to clipboard
The administrator of your Appian environment must set up the following to support your work in this tutorial:
| Location | Action |
|---|---|
| Process Mining | Create a user account for you to use. This account needs Analyst access. |
| Mining Prep | Connect your Mining Prep and Process Mining environments with the shared API key. |
Part 2: Import process dataCopy link to clipboard
Where? Mining Prep
The first step in any Appian Process Mining project is to import data that describes your process. Typically, you need to transform the process data into a format that Process Mining can read. This format is called an event log.
In this part of the tutorial, you'll use CSV files from Process Dining Pizzeria's order processing system in Mining Prep to:
- Add a data set that contains Process Dining Pizzeria's order process data.
- Transform the data set into an event log.
- Load the transformed event log into Process Mining for further analysis.
Let's get started!
Sign in to Mining PrepCopy link to clipboard
To begin, you need to sign into your Mining Prep environment.
To sign in to Mining Prep:
- Go to <sitename>.appianmining.com/mining-prep.
- For example:
appian.appianmining.com/mining-prep
- For example:
- Enter your organization's realm.
- Click NEXT.
- Enter your username or email credentials in Username or email.
- Enter your password in Password.
- Click Sign In.
Add the data setsCopy link to clipboard
It's often the case that your process data is split into a few different files or data sources. In this tutorial, Process Dining Pizzeria's data is in three files: a table of events that occurred as part of the order process, the associated case attributes, and a key that maps location IDs to location names.
You need to add three data sets for each of your CSV files.
Add pizza-order-events.csv as a data set:
- In Mining Prep, go to the Data Management tab.
- Click ADD in the Data Sets section.
- Click SELECT FILE.
- Find and open the
pizza-order-events.csvfile you downloaded earlier. - Click UPLOAD.
The data from pizza-order.csv displays in a data set as shown below:
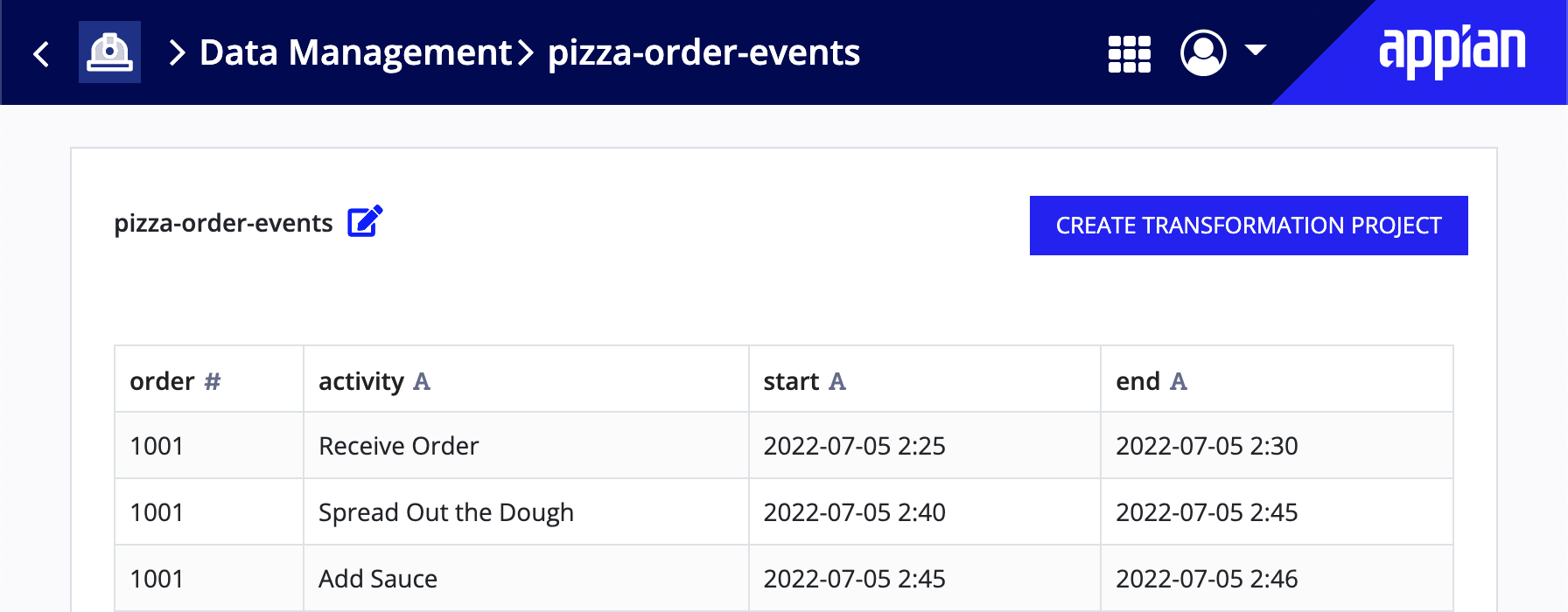
Add case-attributes.csv as a data set:
- Click Data Management in the header bar to return to the Data Management tab.
- Click ADD in the Data Sets section.
- Click SELECT FILE.
- Find and open the
case-attributes.csvfile you downloaded earlier. - Click UPLOAD.
Add location-key.csv as a data set:
- Click Data Management in the header bar to return to the Data Management tab.
- Click ADD in the Data Sets section.
- Click SELECT FILE.
- Find and open the
location-key.csvfile you downloaded earlier. - Click UPLOAD.
Create a transformation projectCopy link to clipboard
Now that you've imported the CSV files into data sets, it's time to add the data sets to a transformation project. Here, you'll transform and combine the data into an event log for Process Mining.
Because Process Dining Pizzeria has a case attribute file and an event file, we'll keep those in separate building blocks. For large data sets, this can help keep your data organized.
To create a transformation project:
- Go to the Transformation Projects tab.
- Click Add.
- Enter
Pizza Order Process. - Click SAVE.
The transformation project is empty, so you need to add one of the data sets you just uploaded. Let's start with pizza-order-events.
To add a data source:
- In the USE DATA SOURCE pane, select pizza-order-events.
- Click USE DATA SOURCE.
The data will populate into the building block.

Transform data with transformation actionsCopy link to clipboard
To transform your data into an event log, you add a sequence of transformation actions that will execute when you load the project into Process Mining. At a minimum, your data needs to have a case ID, event, and time stamp.
Convert datesCopy link to clipboard
In this example, we have time stamps, but they are currently assumed to be of type string as denoted by  . Let's convert the time stamp columns into a proper
. Let's convert the time stamp columns into a proper datetime format.
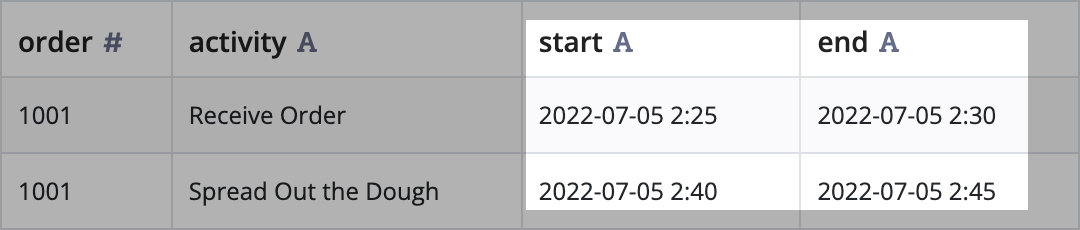
To convert dates:
- Click ADD.
- Select Date Conversion.
- In the DATE CONVERSION pane, select start and end from the dropdown.
- In Select a timezone, select UTC.
- Click PREVIEW to verify the conversion.
Tip: Notice that the data type icons change from string
to datetime  for the start and end columns.
for the start and end columns. - Click SAVE.
That's all you need to do for the pizza-order-events building block for now. Next, let's make a new building block and add the case attributes to it.
Add case attributes dataCopy link to clipboard
Case attributes are characteristics of an entire case such as order cost and order type. It's typical to use multiple building blocks in a transformation project when you have a large amount of data and when event and case data are located in separate files. Building blocks help you organize data in Mining Prep.
To add a new building block:
- Click Pizza Order Process in the header bar to return to the transformation project.
- Click ADD BUILDING BLOCK.
Now we have a blank building block. This should resemble the blank building block you originally added pizza order events to. Let's add the case attribute data here.
To add case attribute data:
- In the USE DATA SOURCE pane, select case-attributes from the dropdown.
- Click USE DATA SOURCE.
Add location dataCopy link to clipboard
One of the most commonly used transformation actions in Mining Prep is Add Data. This allows you to combine multiple data sets into a single building block.
In the current data set, only numeric keys represent locations. Fortunately, the location-key.csv file maps these numbers to a location name.
To add location data to this building block:
- Click ADD.
- Select Add Data.
- In the ADD DATA pane, select location-key from the dropdown.
- Select the LocationID key from the dropdown.
- Select the matching ID key from the dropdown.
- Click PREVIEW to verify that the two tables will correctly combine.
- Click SAVE.
You've successfully combined all of the case attribute data into a single building block! Let's perform a couple more actions to clean up the data.
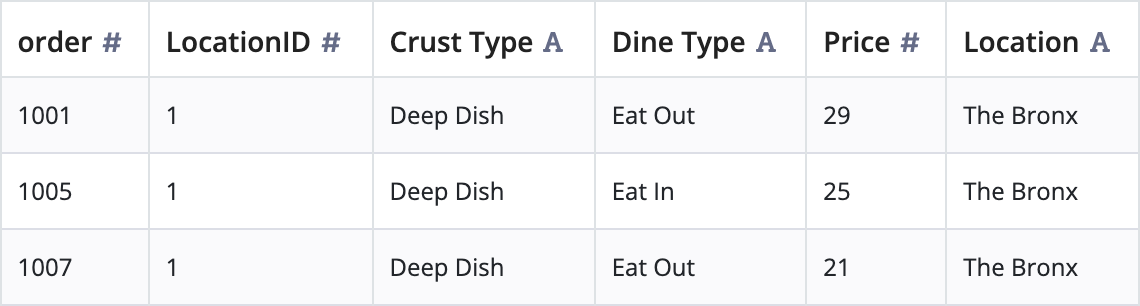
Rename Location and LocationID columnsCopy link to clipboard
Next, notice that there are Location and LocationID columns. Since the data only includes boroughs in New York City that Process Dining Pizzeria delivers to, we can make this more specific. Let's rename these columns to Borough and BoroughID respectively, so that the column more accurately represents your data.
To rename the Location column:
- Click ADD.
- Select Rename Column.
- In Select column to rename, select Location.
- In New column name, enter
Borough. - Click Preview to verify the name change.
- Click SAVE.
To rename the LocationID column:
- Click ADD.
- Select Rename Column.
- In Select column to rename, select LocationID.
- In New column name, enter
BoroughID. - Click Preview to verify the name change.
- Click SAVE.
Merge Borough and BoroughID columnsCopy link to clipboard
The merge transformation action combines data from two columns together. This is helpful when you have related data that you'd like to group and view together in Process Mining.
To merge columns:
- Click ADD.
- Select Merge Columns.
- In Select columns to merge, select Borough and BoroughID in that order.
- In New column name, enter
Borough_with_ID. - In Separator, enter
-and add a space before and after the hyphen. - Click Preview to verify the name change. For example, it should display like this:
The Bronx - 1. - Click SAVE.
Identify data propertiesCopy link to clipboard
Once your data set has been transformed, you're ready to identify the required data properties. In order for data to be analyzed by Process Mining, it must contain a case ID, event, time stamp, and optionally, case attributes.
Since our transformation project has two building blocks, we'll have to identify the case ID in both places.
Identify the Case ID in case-attributesCopy link to clipboard
The case ID ties together an entire sequence of events, comprising a unique case or single occurrence of a process.
Tip: In this example, you can use the order number as the case ID, since it represents a unique case.
To identify the case ID for case-attributes:
- Click CASE ID in the IDENTIFY section.
- Use the dropdown to select the order column.
- Click SAVE.
Case attributesCopy link to clipboard
Case attributes are characteristics of an entire case. When you identify these attributes in Mining Prep, Process Mining makes them available as dimensions in dashboards to help with your analysis. In this tutorial, Process Dining Pizzeria's case-attributes.csv file contains all of the case attributes.
To identify case attributes:
- Click CASE ATTRIBUTES.
- In Numerical Attribute Columns, select Price.
- In Categorical Attribute Columns, select Borough, Borough_with_ID, Crust Type, and Dine Type.
- Click SAVE.
Note: Why didn't we select these attributes when identifying the event? All of these attributes are case attributes, not event attributes. Case attributes apply to an entire case and don't change from event to event. Event attributes apply separately to each event.
Identify the Case ID in pizza-order-eventsCopy link to clipboard
We also need to identify the case ID for pizza-order-events. When we transform and load the data into Process Mining, the shared case ID will tie the cases together.
To identify the case ID for pizza-order-events:
- Click Pizza Order Process in the header bar to return to the transformation project.
- Click pizza-order-events.
- Click CASE ID in the IDENTIFY section.
- Use the dropdown to select the order column.
- Click SAVE.
EventsCopy link to clipboard
Events represent how and when a process activity occurred. In this example, these are stored in the pizza-order-events building block.
To identify events:
- Click EVENTS in the IDENTIFY section.
- Click ADD EVENTS.
- Select MULTIPLE EVENTS.
- In Name of Event Group, enter
Order activity. - In Event Name Column, select activity.
- Select START & END.
- In Start, select start.
- In End, select end.
- Click SAVE.
Nice work! You're now one step away from analyzing this data in Process Mining.
Load event log into Process MiningCopy link to clipboard
At this point, you've prepared the data to be transformed into a suitable format for Process Mining analysis. All that's left is to transform and load it into Process Mining.
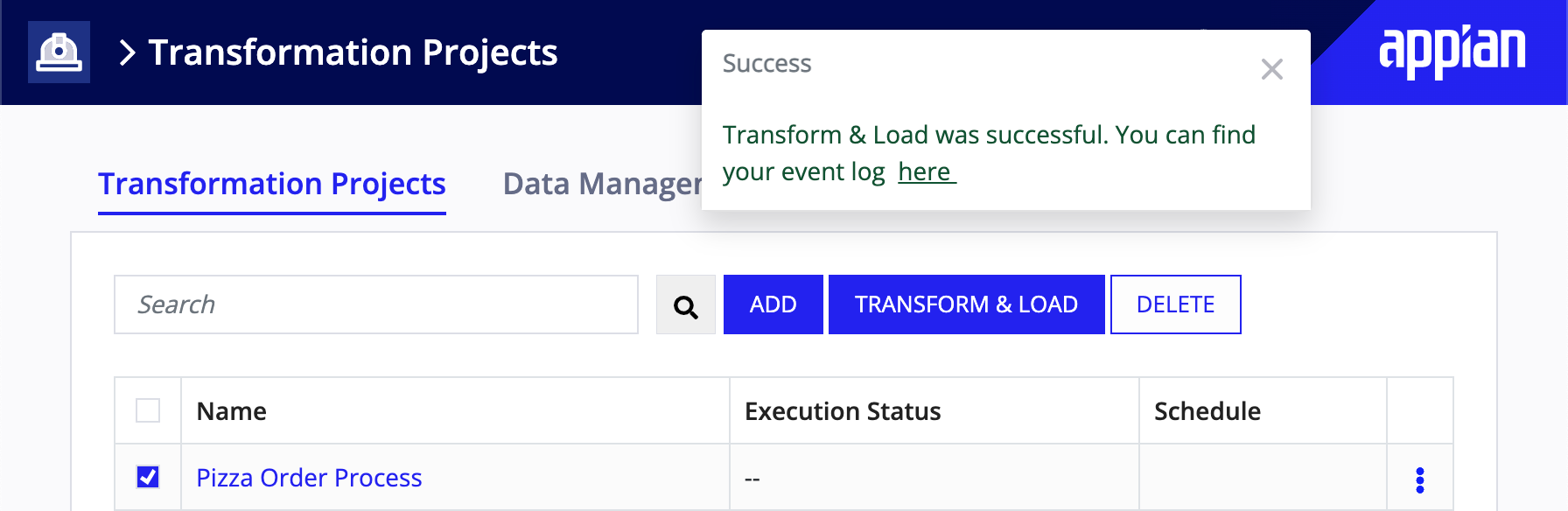
To transform and load the project:
- Go to the Transformation Projects page.
- Select the Pizza Order Process transformation project.
- Click TRANSFORM & LOAD.
- Verify that your process mining environment is selected in Where would you like to export your project to?.
- Click OK.
You did it! Now it's time to start digging deeper into this data and uncovering actionable insights.
Part 3: Discover insights into a processCopy link to clipboard
Where? Process Mining
The process data is now ready for Process Mining analysis.
In this part of the tutorial, you'll use Process Mining's capabilities to:
- Visualize the order process.
- Identify undesirable process deviations.
- Perform root cause analysis to determine the causes of deviations.
- Create a dashboard to uncover long order wait times.
- Determine actions you can take to optimize the process.
Sign in to Process MiningCopy link to clipboard
To sign in to Process Mining:
- Go to <sitename>.appianmining.com.
- For example:
appian.appianmining.com
- For example:
- Enter your organization's realm.
- Click NEXT.
- Enter your username or email credentials in Username or email.
- Enter your password in Password.
- Click Sign In.
Select your processCopy link to clipboard
After you sign in, you should see the Pizza Order Process event log in the management hub. Most actions you take in Process Mining are done through the context of the log you select. Notice that the sidebar is empty; this is because you need to select the Pizza Order Process event log to proceed.
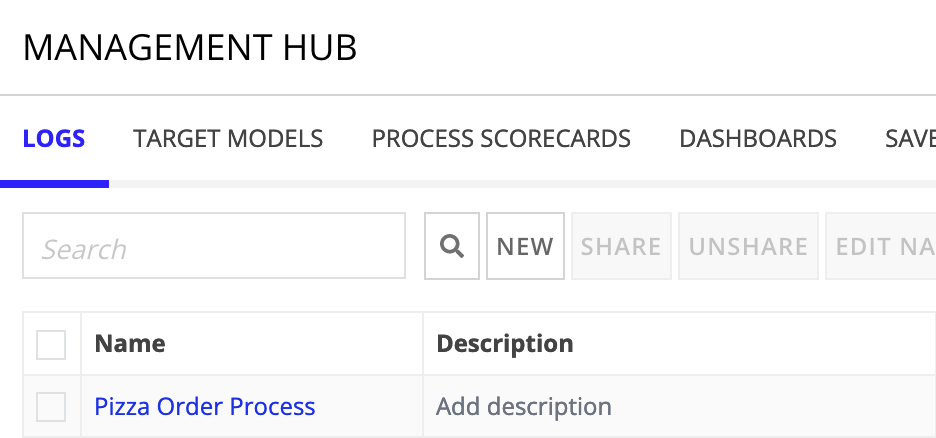
To select the event log that describes your process:
- In the management hub, go to LOGS.
- Click the Pizza Order Process name.
Notice that the Pizza Order Process event log is now active within Process Mining. Models, deviations, filters, and insights are now all viewed through the context of this process.
View discovered modelCopy link to clipboard
When you select an event log, you're immediately navigated to the Models page. Here, you can see a visualization of your process as described by the event log.


While it's useful to visualize how your process actually executes, it's even more useful to compare the actual execution with how you expect it to execute.
Upload target modelCopy link to clipboard
The discovered model tells you how your process is actually occurring, but how do you uncover insights into specific behavior? A great approach is to upload a target model, which is a BPMN file that describes how you expect your process to run. Process Mining performs conformance checking against this model to tell you when certain activities are skipped, out of order, or require additional work.
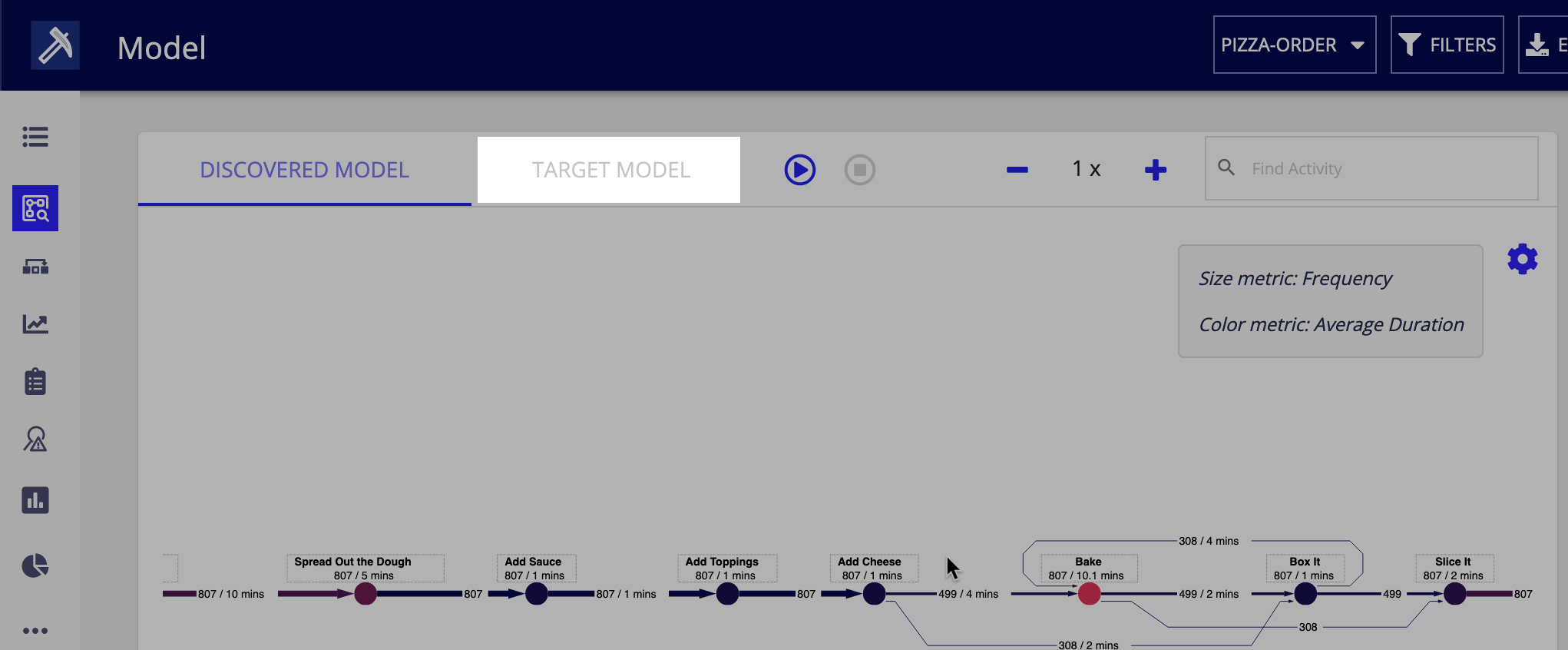
Let's upload the target model BPMN file provided in Step 1.
To upload a target model:
- On the Model page, click the TARGET MODEL tab.
- Click UPLOAD NEW MODEL.
- Find and select
target-pizza-order.bpmn. - Click SAVE ALIGNMENT.
- Go to the TARGET MODEL tab.
When you view the target model, you'll see how your actual process compares. For more information, see target models.
Filter variant groupsCopy link to clipboard
Variant groups are collections of variants based on the frequency they occur. Variants are alternate paths that a process can take. Slide the Number of Variant Groups slider to reveal more process variants. Let's show all variants.
To show all variants:
- Slide the Number of Variant Groups slider so it spans from 1 General to 5 Exceptional.
Notice that additional deviations are uncovered in the target model. Notably, there are several variants where the Slice It activity is skipped.
Let's see what other deviations exist in our data on the Deviations page.
Identify deviationsCopy link to clipboard
Deviations are changes to an activity that negatively impacts a process's normal execution. These are often good candidates on which to perform root cause analysis. Root cause analysis helps you determine why a deviation is occurring, so you can take action to eliminate it.
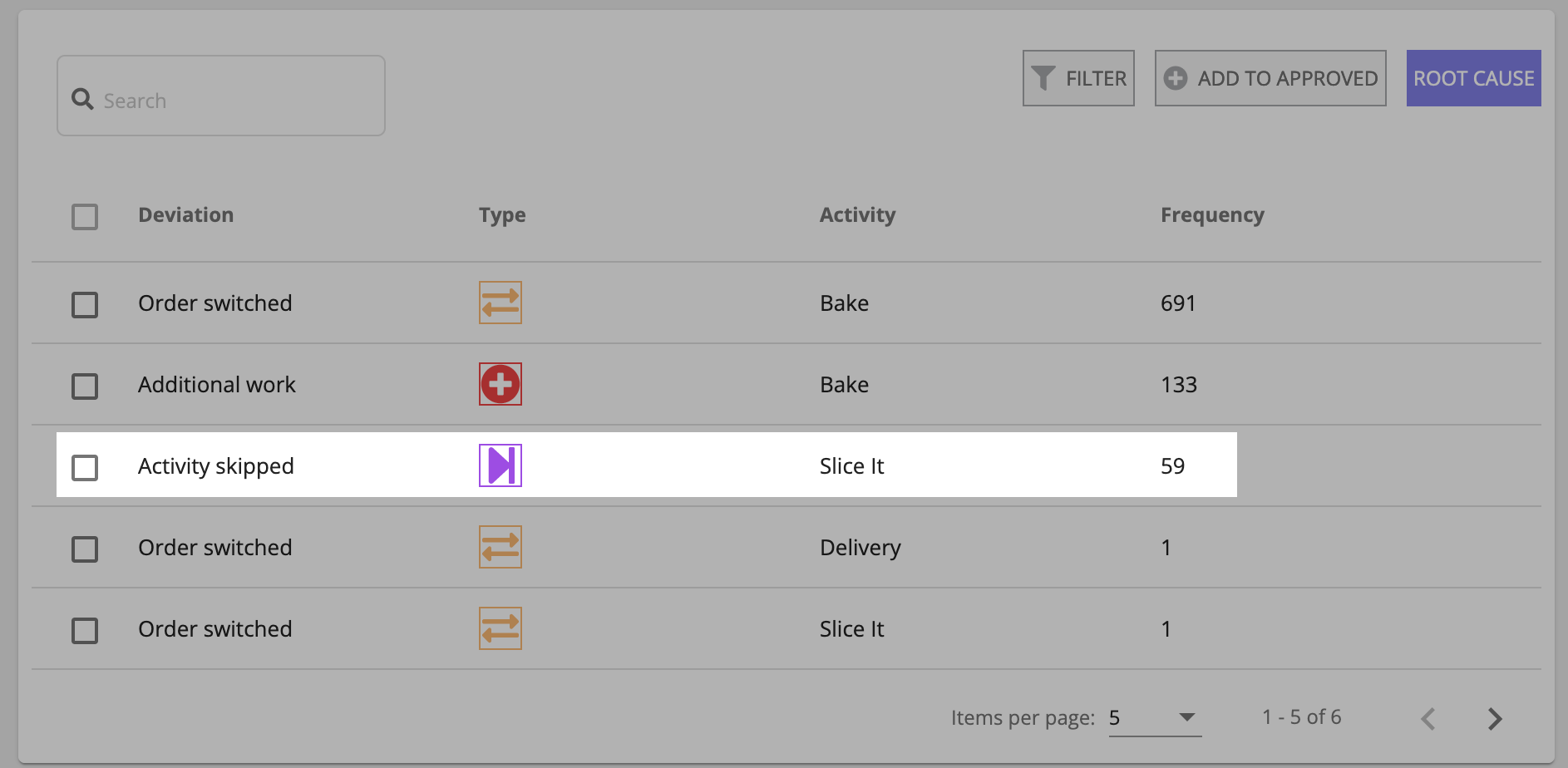
To identify deviations:
- Go to the Deviations
 page.
page. - Look over the list of deviations.
Notice that there are three different types of deviations in the process. For more information on the possible types of deviations, see Deviation types.
Let's use the Activity skipped deviation that we just looked at to perform root cause analysis.
Perform root cause analysisCopy link to clipboard
Root cause analysis helps you determine why a deviation is occurring, so you can take action to eliminate it. In our use case, we want to see why the Slice It activity is getting skipped in 59 of the cases.
To perform root-cause analysis on a deviation:
- Go to the Deviations page.
- Select Activity skipped.
- Click ROOT CAUSE.
- Click RUN.
You are navigated to the Insights page, which displays the results of root cause analysis. Let's walk through this page to uncover insights.
Make conclusions from insightsCopy link to clipboard
The Insights page displays the results of root cause analysis.
At the top of the page, you'll notice that the Slice It activity is skipped in 5.9% of the cases in the log. This is a significant enough problem that customer support has been notified that pizza was unsliced.
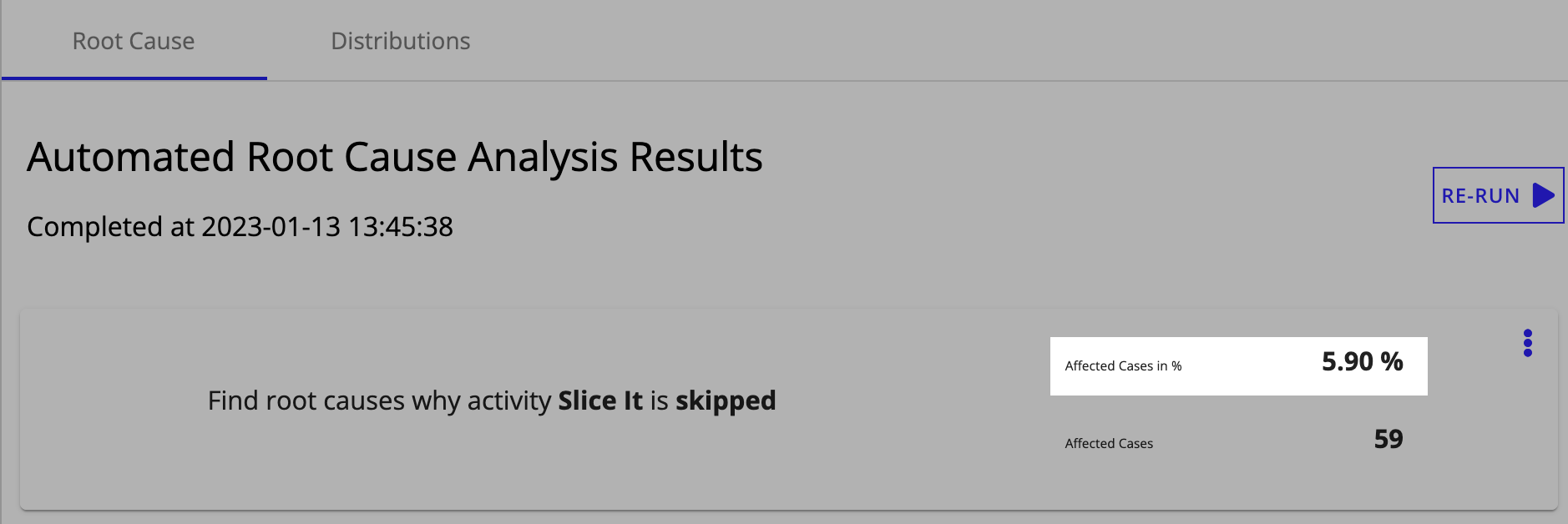
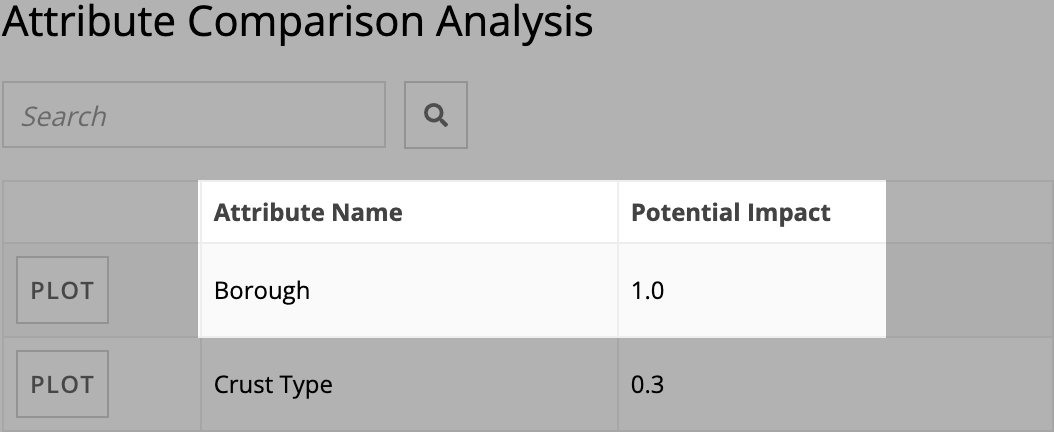
The Attribute Comparison Analysis section indicates how likely a specific attribute is impacting the process outcome. The higher the number in the Potential Impact column, the greater the likelihood. Notice that the Borough attribute name has a potential impact of 1.0. This points to a strong likelihood that the location of business is leading to the deviation.
To dig deeper, we can plot the values of the Borough attribute. It's important to distinguish between the attribute values to see if any stand out as the culprit.
Click PLOT in the Borough attribute row to display a graph of how the Borough attribute value is distributed throughout your data.
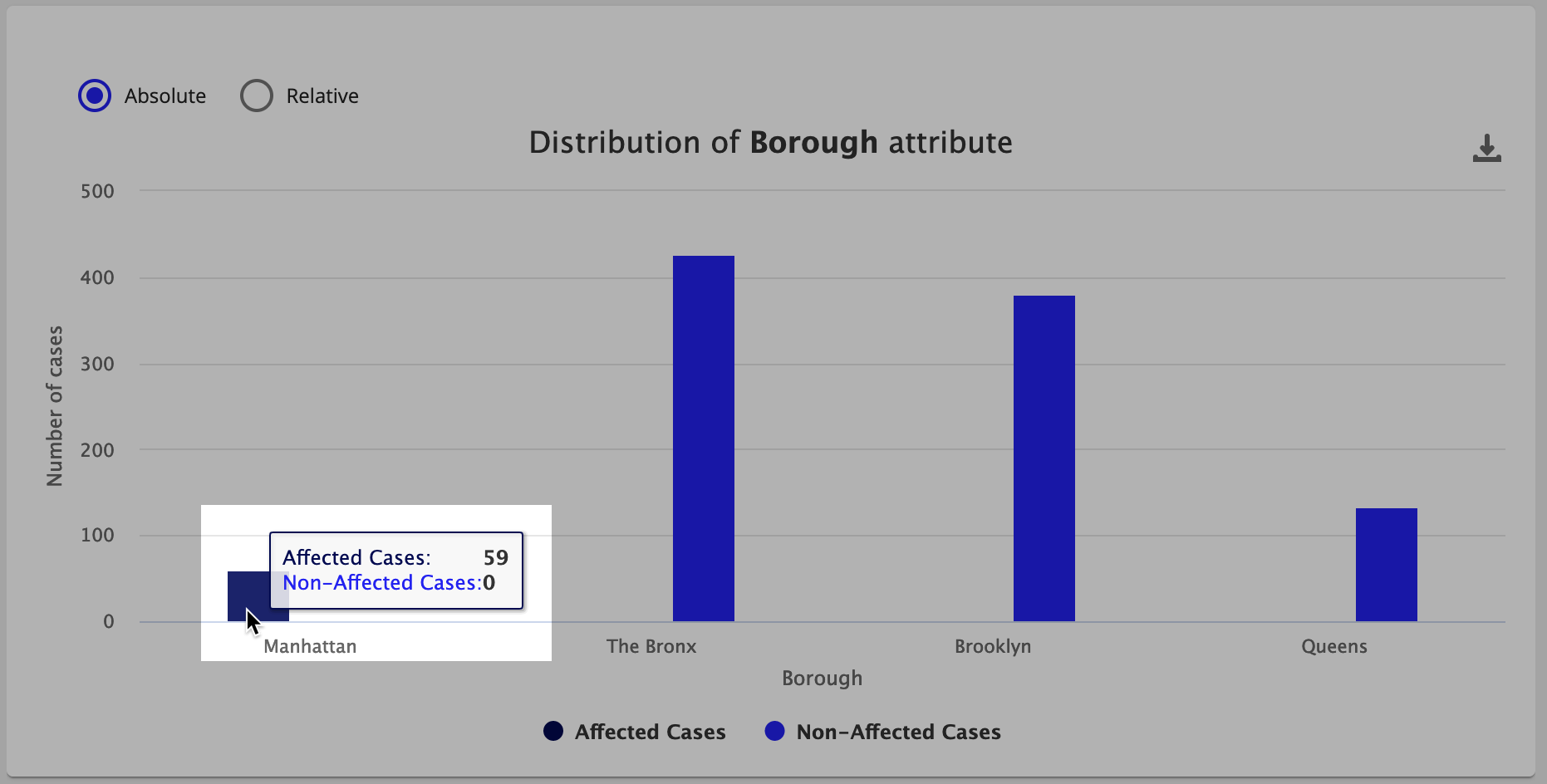
Notice that the Manhattan location contains all of the affected cases! This is an important data point, which is further backed up by the Causal Rules for Affected Cases section. In this other section we see that when Rule Borough = Manhattan, there is 100% coverage of affected cases.

What could this mean? There is a strong chance that the restaurant in this location is correlated with pizzas going out without being sliced. This could be a number of factors, such as inadequate training or the restaurant being understaffed and overworked.
Create a dashboardCopy link to clipboard
You've already looked into why pizzas are arriving unsliced, but you still need to look into orders taking too long. Let's create a dashboard to look into the wait time between Receive Order and Bake activities. Here, you can use the Borough_with_ID categorical attribute you defined earlier to see if there is any correlation.
To create a dashboard:
- Go to the Dashboard
 page.
page. - Click Enable Edit Mode
 .
. - In Charts, select Column chart.
- In Chart Title, enter
Wait Time by Borough. - Configure the following chart Metric settings:
- Select Waiting/transport time.
- From: Select Receive Order.
- To: Select Bake.
- Select Average duration.
- Configure the following chart Dimension settings:
- Select the Borough_with_ID categorical attribute.
- Click UPDATE.
- Click and drag the edge of the chart you just created to make it bigger.
- Click Exit Edit Mode
 .
.
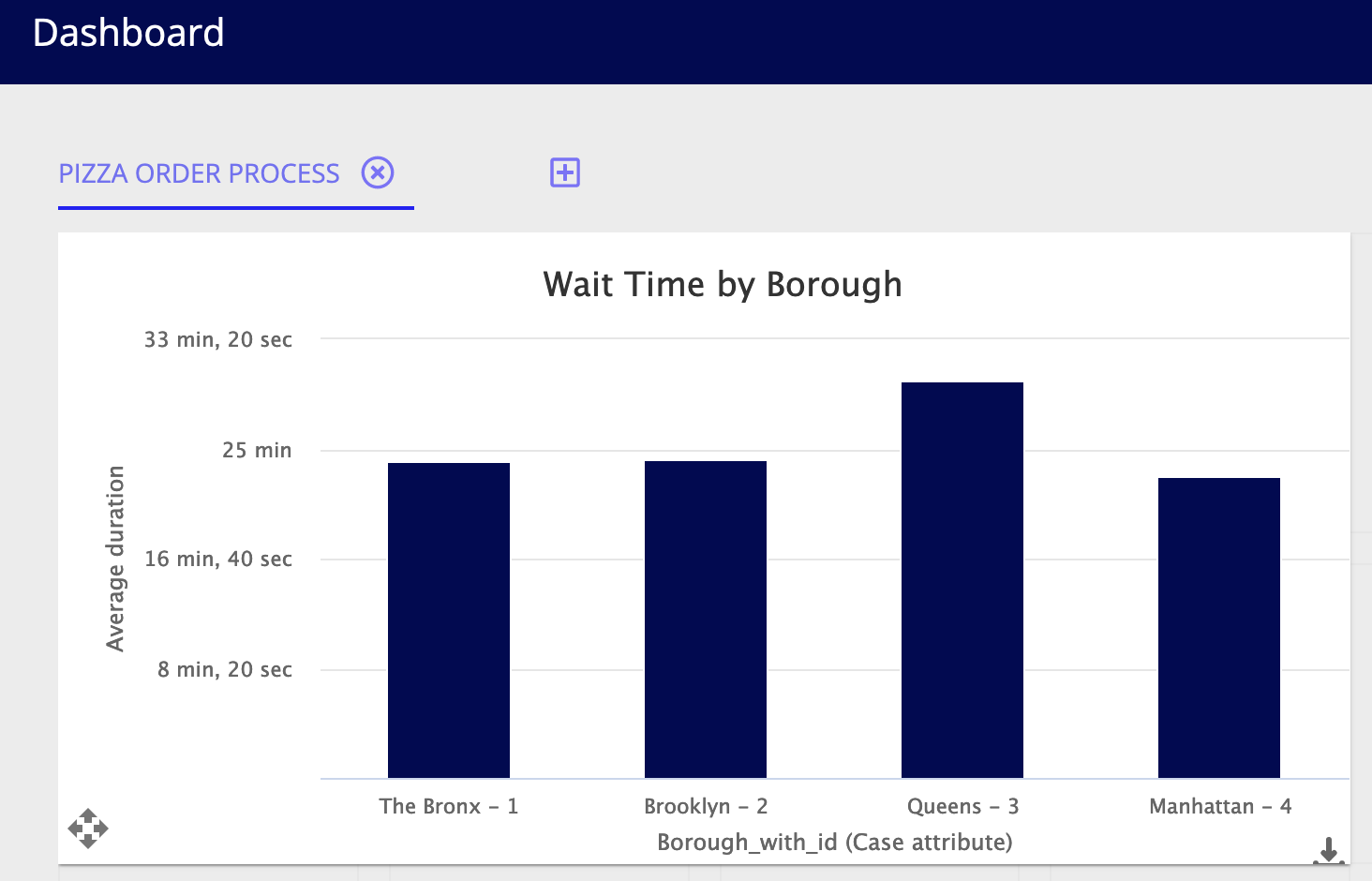
Interpret the dashboardCopy link to clipboard
Dashboards give you a high-level view of metrics and dimensions in your data. In the dashboard you just created, it's clear that the Queens borough stands out from the rest with its longer wait times from Receive Order to Bake activities.
The great part of a dashboard is you can now monitor how this metric improves over time. For example, let's say you make changes to the process to better automate how employees receive and accept orders. When you upload new data to Process Mining, you'll be able to track how that affected the metrics you are tracking.
What's next?Copy link to clipboard
Now that you've uncovered insights into what is causing process deviations, it's time to implement an improvement to your process. Fortunately, Appian is well-suited to creating, enhancing, and automating processes.
To improve this process, you could:
- Automate more activities to improve speed and accuracy.
- Increase the number of employees at the affected location to reduce workloads.
- Provide additional training to the affected location to improve accuracy.
Process mining is a cyclic improvement cycle. After you try techniques to improve your process based on the initial goals you defined, you can schedule automatic transform and load updates to track your progress towards goals. You can also use additional Process Mining capabilities, like dashboards and process scorecards, to track and share summaries of process performance.
Success!Copy link to clipboard
Congratulations on finishing this tutorial!
For additional information about other Process Mining use cases, see Use Cases.