
OverviewCopy link to clipboard
Enterprise data is often vast, complex, and mission-critical, so businesses take great care to carefully construct a data fabric that grows with their automation processes.
This topic outlines several best practices for building a scalable, performant, and AI-ready data fabric. Review and implement these suggestions as you create record types to ensure a strong foundation for your applications.
Use synced record typesCopy link to clipboard
Appian's data fabric is powered by record types with data sync enabled. We call these synced record types.
As a best practice, you should enable data sync on all new record types. This allows you to take advantage of powerful sync-enabled features and work with performant, up-to-date data.
If your existing record types do not have data sync enabled (unsynced record types), you can create new synced record types to use in Process HQ and in new development. Learn more about how you can incorporate synced record types into your existing applications.
Identify the best way to work with large data sourcesCopy link to clipboard
Each record type with data sync enabled can sync up to 4 million rows of data from a source. While this is a significant amount of data, very large data sources or growing data sources may require you to adapt your data model so you can access all the data you need.
Depending on your business case, you can easily adapt your data model:
| If… | Then… | For Example |
|---|---|---|
| You only need the most recent data from a large database table. | Enable Keep data available at high volumes on your record type. This sync option will dynamically sync the latest 4 million rows of data. | Your Event History record type captures numerous events a day, and is expected to exceed the synced row limit. You could enable this sync option so Appian can dynamically sync the latest data, so if you do have more than 4 million events, only the latest and most relevant are synced. |
| You only need a portion of the data from a large data source. | Configure sync filters on your record type to choose which data to sync in Appian. | You have a database table with 5 million rows of support cases, and you need to track the progress of all open cases. You could create a record type called Open Cases and configure sync filters to only sync records that have a status of Open or In Progress. |
Provide meaningful metadataCopy link to clipboard
Data is often more valuable and easier to understand if it's clear how that data was created, what it's used for, or what it means. Together, these details establish the context, and help people and technology understand how your data works together.
Metadata is essential to establishing context for your data, and therefore essential for making sense of it. These recommendations mention specific metadata to include in your data fabric.
Unique plural record type namesCopy link to clipboard
In places like the Data Catalog of Process HQ, users see the plural names of your record types, so it is important that each record type has a unique name. Sometimes this means you'll need to edit the system-generated plural name for a record type.
Example: You have two record types with the following singular names with different purposes: CM Employee and HR Employee. By default, Appian suggests CM Employees and HR Employees as the plural names, respectively. We recommend that you provide more descriptive plural names, such as Case Employees and Company Employees, so users and technology can more quickly distinguish between similarly named record types.
Record type descriptionsCopy link to clipboard
Descriptions also help provide business context to users. The clearer the descriptions are, the more information users will have when exploring the data model. Additionally, this information helps make AI features more effective at querying your data by providing valuable context. These descriptions should be good enough that a person who isn't familiar with your data model can understand it after reading these descriptions.
Tip: If the record type will appear in Process HQ, avoid any developer terminology (like "record type" or "data sync enabled") in the description since it will be visible to business users.
Example #1: A record type called Case Type contains both categories of cases (such as Commercial or Public Sector) and case types (such as Demolition or Construction). Based on field names alone, a person (or AI model) might have trouble distinguishing these two fields and the data each one contains. To help make this clear, the following description would be appropriate:
Contains the different types of cases. There are categories of cases and there are types within those categories. If the isCaseCategory field is set to true, the case type is a category, otherwise it is a type within a category. For example, Commercial is a category and Demolition a type within the Commercial category.
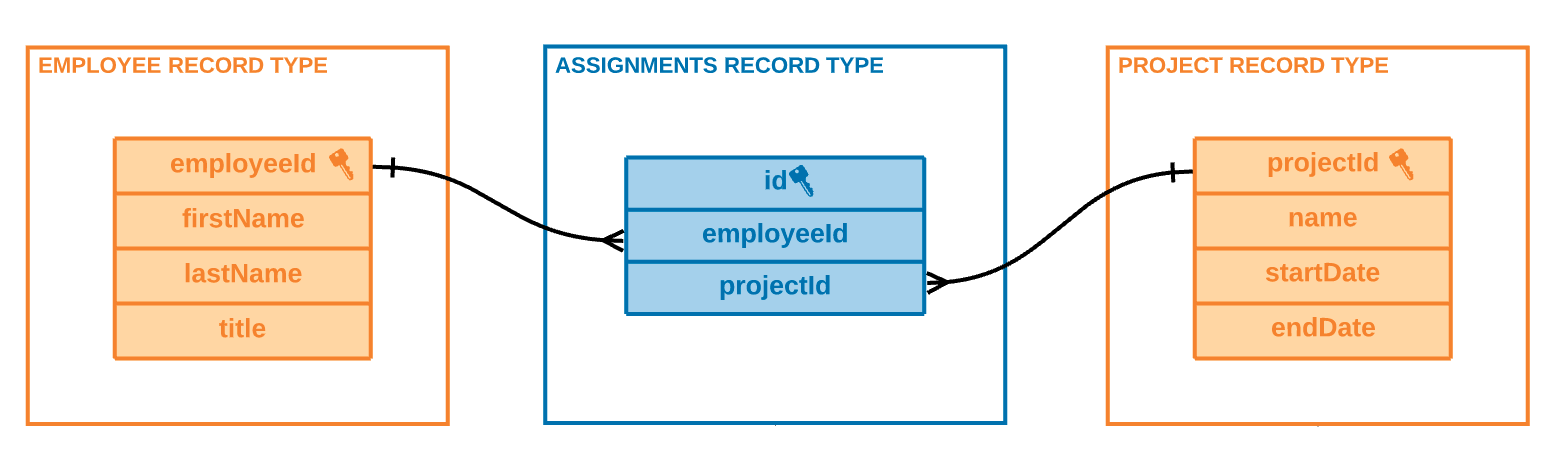
Example #2: To specify a many-to-many relationship between Employee and Project, you need to use a third record type, called Assignments. The third record type should include a description such as:
Maps employees to projects. For example: Employee A and Employee B work on Project 1, Employee B and Employee C work on Project 2. Project 1 and 2 each have two employees assigned to work on them. Employee A and Employee C each work on one project, Employee B works on two projects.

Field display names and descriptionsCopy link to clipboard
You can add display names and descriptions to fields in your record types. Good field names, display names, and descriptions provide users and AI with additional context. Consider listing synonyms or acronyms in your descriptions to provide this context.
Example: In the Case record type, each record has a dueDate field which contains Date and Time data. You also have a custom record field (daysTilDue)that calculates the difference between today's date and the due date, so you can quickly see how many days are left until the deadline.
To help a person or AI model understand the information that this custom record field contains, you could add a display name and field description that contains any synonyms or acronyms users might use.
- Field display name:
Days until deadline - Field description:
Number of days left until a deadline; or number of days until service-level-agreement (or SLA).
Relationship namesCopy link to clipboard
As you configure your record fields and relationships, ensure that your field names and relationship names can be easily understood by other developers and end users. These names will appear in records-powered components and in Process HQ when users build their own reports. If you plan to use AI in your applications, the AI models will also use this information to better understand your data.

Use camel casing to format your field names and relationship names. For example, a field for last names should be formatted as lastName. Appian will automatically convert camel cased fields and relationship names to title case in end-user workspaces, so they're easy for end-users to read. You should also avoid adding application prefixes to your relationship names since these names will also appear to end users. For example, if you have a relationship name like nacCustomer, you should update it to customer.
Learn more about preparing data for self-service reporting in Process HQ.
Create bi-directional record type relationshipsCopy link to clipboard
Add relationships to any and all related record types, on both sides of the relationship. These relationships make easier for both people and AI models to find the information that might be related to each other.
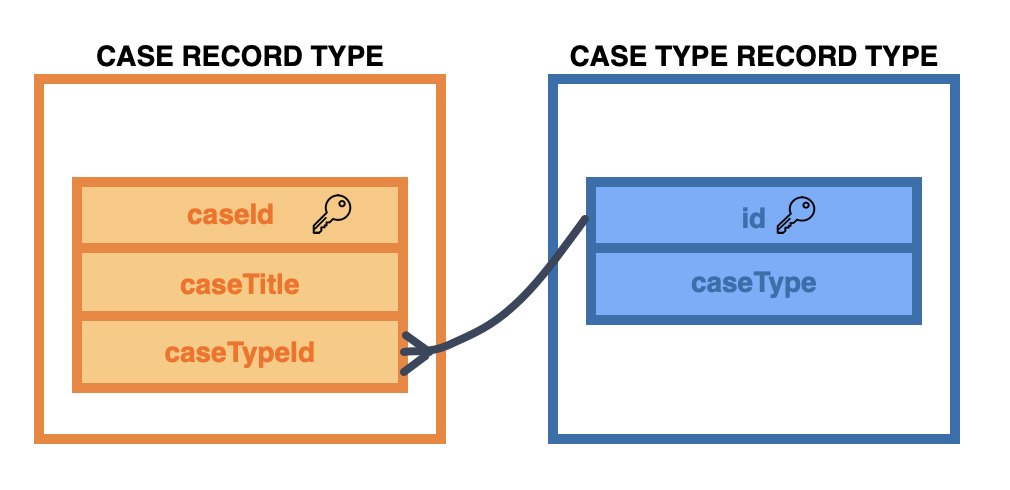
Example: You have two record types: Case and Case Type. A case can only have one case type, but there can be multiple cases of the same type. Therefore, Case has a many-to-one relationship with Case Type, and Case Type has a one-to-many relationship with Case.
Ensure you add relationships to both record types, with common fields mapped appropriately. Appian suggests these relationships for you as well.
Create custom record fieldsCopy link to clipboard
Sometimes, a record type won't explicitly contain the necessary data to answer a question. For example, you may need to aggregate, extract, or change your existing data to show specific insights. This is a good opportunity to use custom record fields.
Example: You have an Order Item record type which contains fields like cost and salesPrice. You can create a profit field to the record type, which subtracts cost from salesPrice.
See additional examples of when to use custom record fields.
Store lookup data in a separate record typeCopy link to clipboard
Lookup data represents a list of static values. These values don't change very often, and they can be shared across multiple record types. To easily maintain static data, and avoid duplicating data, you should create separate record types for lookup data.
For example, in an application, you may have a Customer record type and an Employee record type. In both record types, you need to reference the state a person lives in. To avoid adding a state field on each record type that could potentially store the information differently (using state abbreviations versus using the full state names), you could create a State record type. Then, using record type relationships, you can relate the State record type to both the Customer and Employee record types so they can easily reference a person's home state.
Tip: You can easily generate a new related record type to hold your lookup data by adding a choice list field. You can edit the choice list field values, as well as any other source data, directly from the Data Preview page of the related record type and download the database script for those changes at the same time.
Track record eventsCopy link to clipboard
Record events allow you to track what happens in your applications, with minimal configuration on your part. Once you start tracking record events, you can display your event data as an activity log to business users or use that data to drive process improvements for your organization.
We recommend configuring record events on the record types that relate your major business processes. For example, in a Case Management application, you should configure record events on the Case record type to track events related to creating and managing cases.
Review the guidelines before configuring record events.
Make record types available in data fabric insightsCopy link to clipboard
Within Process HQ, users can only access and ask questions about the record types that are available as datasets in the Data Catalog. Choose the record types you want to make available as datasets in Process HQ to enable your users to gain insights.
Protect sensitive data with record-level securityCopy link to clipboard
Enterprise data often includes information that must be protected for business, privacy, or regulatory reasons. For example, you may want to restrict customer information to the salesperson working with a client, or you may need to allow only managers and executives to view company financial data.
As you construct your data model, identify the information that requires protection and the users or groups that are allowed to access it. When you build the record type that includes sensitive data, you can then configure security controls to ensure protected record data can only be viewed by certain users or groups.
Appian's AI features also respect all record type object and record-level security configurations. If AI Copilot provides answers that don't seem correct, it may be because of how record-level security is set up for a given user.
To learn more about the security features available for record types with data sync enabled, see Record-Level Security.
AI-specific best practicesCopy link to clipboard
Data isn't just the foundation of your applications, it's also the key to making the most of artificial intelligence (AI) capabilities. Building an intentional, high-quality data architecture with Appian's data fabric will enable you to easily integrate powerful AI features into your workflows.
This section includes specific best practices for how to create record types and other data objects in Appian so your applications are setup to take advantage of AI.
Store usernames consistentlyCopy link to clipboard
Usernames come in a variety of formats, such as firstname.lastname (john.smith), email addresses (john.smith@acme.com), or first initial + last name (jsmith). To help users and AI models parse this information, use a format that includes the user's first and last name.
Example: The Case record type stores assignee usernames as j.smith. A user may ask AI Copilot a question such as "How many cases are assigned to John Smith?". However, the username doesn't include the first name. To help the AI model successfully reference the username field when answering this question, use a format that includes the first and last name in the username.
If you're having trouble getting accurate responses for questions including usernames, contact Appian support to update your site's properties to use the appropriate format.
Describe fields that indicate soft deletions of recordsCopy link to clipboard
It's common to build a "soft deletion" mechanism into a record type. For example, setting the value of a field like isActive to false retains the data but filters it from most queries.
For AI features to return current data to the user, use these fields to filter out the soft deleted data by adding this instruction to the descriptions for these fields.
Example: If you have a field called isActive of type Boolean for a record type containing groups in a work department, you could add the following description:
Indicates if the group still exists or not. When asking AI Copilot to return a list of departments, this field should be used to filter for only active departments, unless otherwise stated.
Indicate business reasons why a field may be emptyCopy link to clipboard
Sometimes fields in a record type could be empty. This could be a data entry issue that may cause issues with queries. Other times, a field could be empty for legitimate business reasons, so it's important to add this to the description of the field.
Example: You have an Employee record type with a startDate and an endDate fields. The endDate field may be empty for employees who still work at the company. In the field description, add something like:
The date an employee leaves the organization. If this field is empty, it means the employee is active.
Test to see if changes have the desired effectCopy link to clipboard
When you use AI in your applications, your data is analyzed by an AI model. So by integrating these best practices, you are effectively engineering your data to be easier to analyze. This is more of an art than a science. Make sure to test and confirm your changes have the desired effect.
Data fabric development checklistCopy link to clipboard
To help you follow Appian's recommended process for designing your data fabric, use the following checklist to ensure you've met the baseline requirements:
- Research, understand, and reflect stakeholders needs in your model's design.
- Enable data sync on your record types. Data sync is required to use record type relationships, custom record fields, and other powerful features.
- Identify the best way to work with a large data source. This can be using sync filters, or by enabling the Keep data available at high volumes sync option.
- Create record types for each of your business concepts.
- Create record types for lookup data, and add record type relationships to connect it to other record types.
- Configure record events on each record type that represents a major business concept.
- Convert fields like
usernameorgroupto the Appian data types User or Group. - Format field names using camel casing, and ensure they are easily understood by other users.
- Format relationship names using camel casing and remove application prefixes from the names.
- Configure record-level security to determine who can view which records.