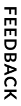| Google has deprecated legacy versions of AutoML services, which directly impacts IDP's core functionality. Additionally, the IDP application was deprecated with Appian 23.2. Customers who wish to use the application will need to refactor plug-ins using AutoML. |
Up to this point, companies that needed to extract data from documents and forms had two options: slow, labor-intensive manual entry or outdated, hard-to-customize optical character recognition software.
But if you have Appian, you have another option: Appian's Intelligent Document Processing (IDP) application. We were so excited about Appian Document Extraction that we couldn't wait to get you started quickly. With IDP, you can automatically extract data from forms in no time. Not only that, we've made it available automatically, as part of the platform.
What does it do? The IDP application uses machine learning and artificial intelligence to quickly extract data from forms for use in your Appian applications. It even gets smarter and better the more you use it.
Read on to get an overview of the IDP application, including how it works, how the data moves in IDP, and some recommendations on how to get started with the application.
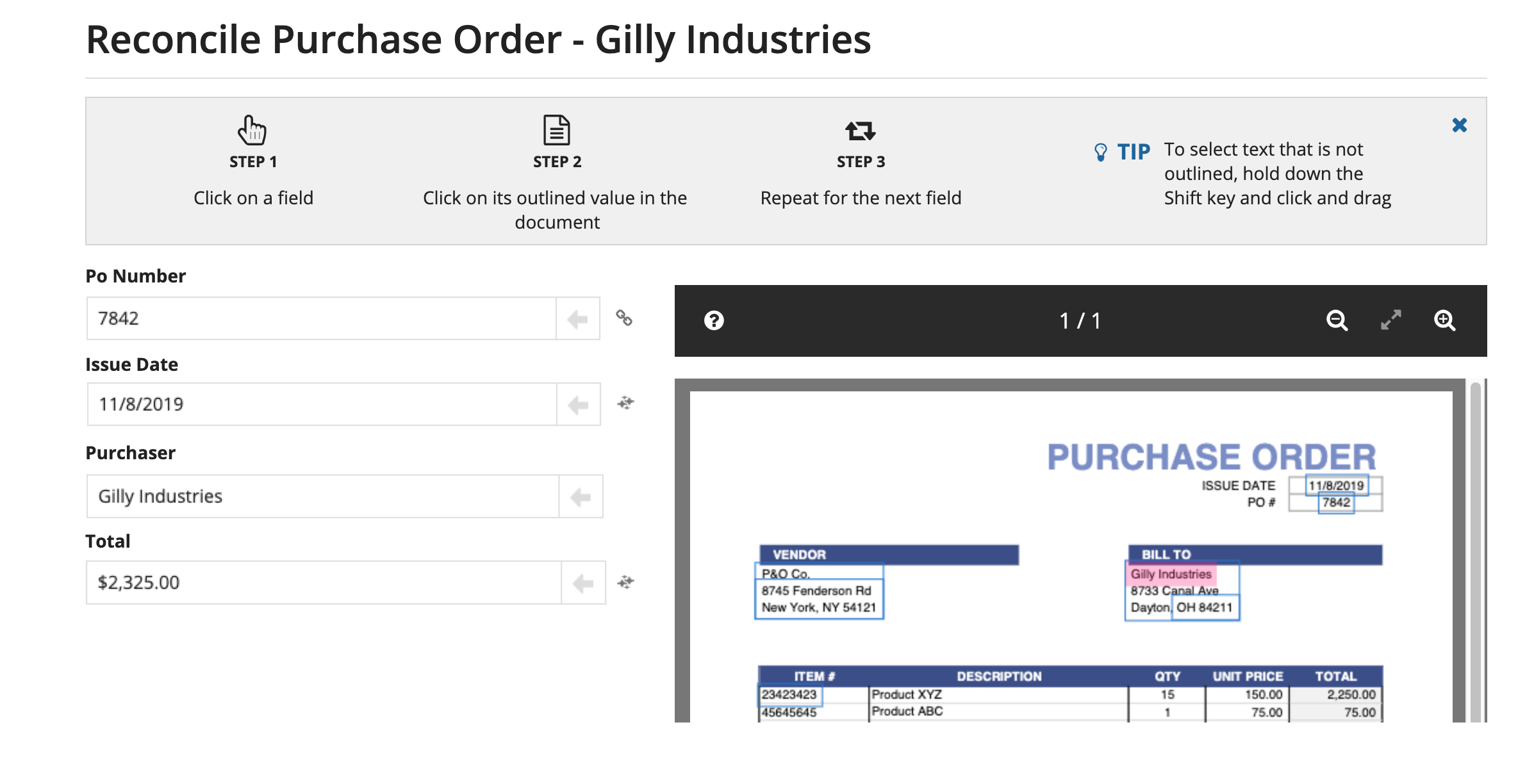
The IDP application uses Appian Document Extraction to transform unstructured data from PDF documents into structured data. This data can then be stored in your database to be used by your applications. In addition, it adds an initial classification step to identify your documents using machine learning services that are available for free.
It works best with fairly standard forms, such as invoices, that tend to contain similar information in each document. For example, almost all invoices have an invoice number and total, and almost all purchase orders have a PO number and purchaser. IDP doesn't require these forms to be standardized, it just requires them to have similar information on each form. See Appian Document Extraction for more information on what types of documents work best for data extraction.
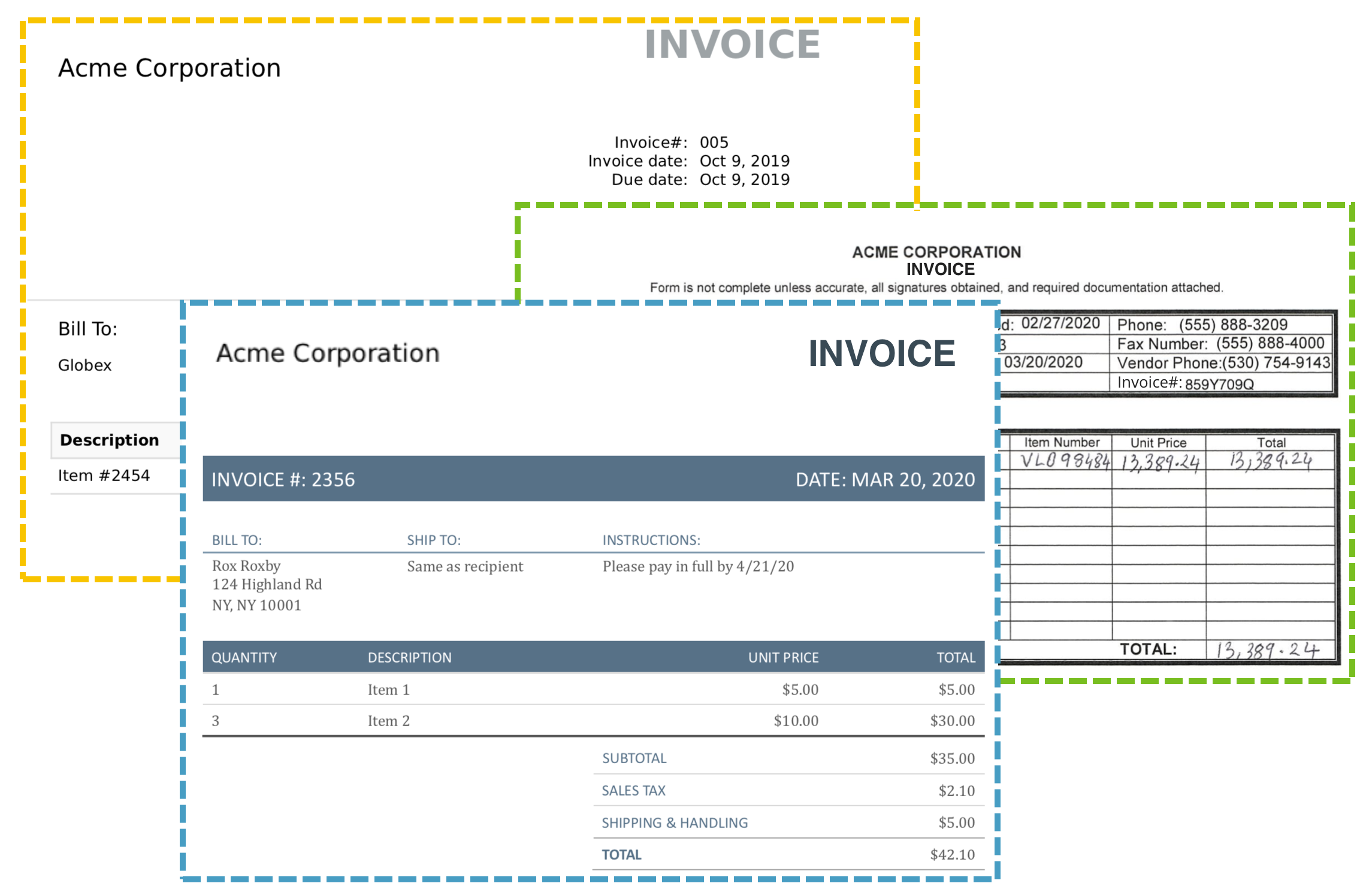
Processing documents in IDP consists of two steps: classification and extraction.
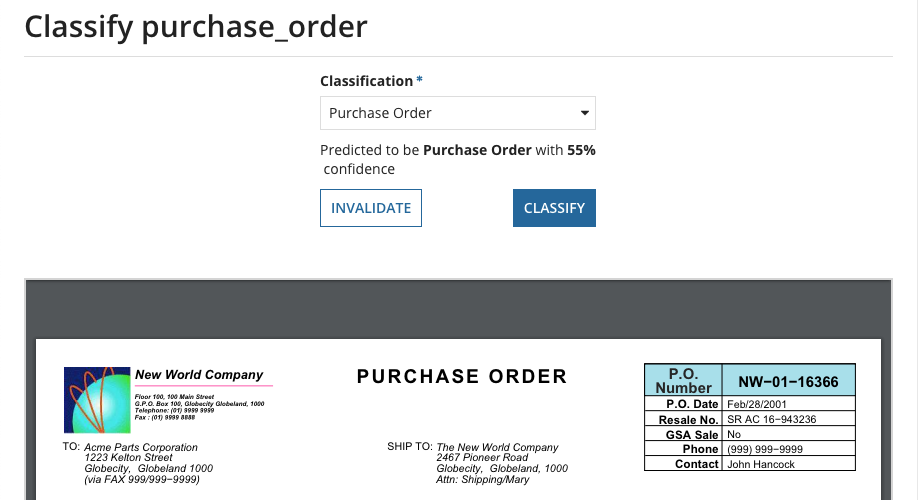
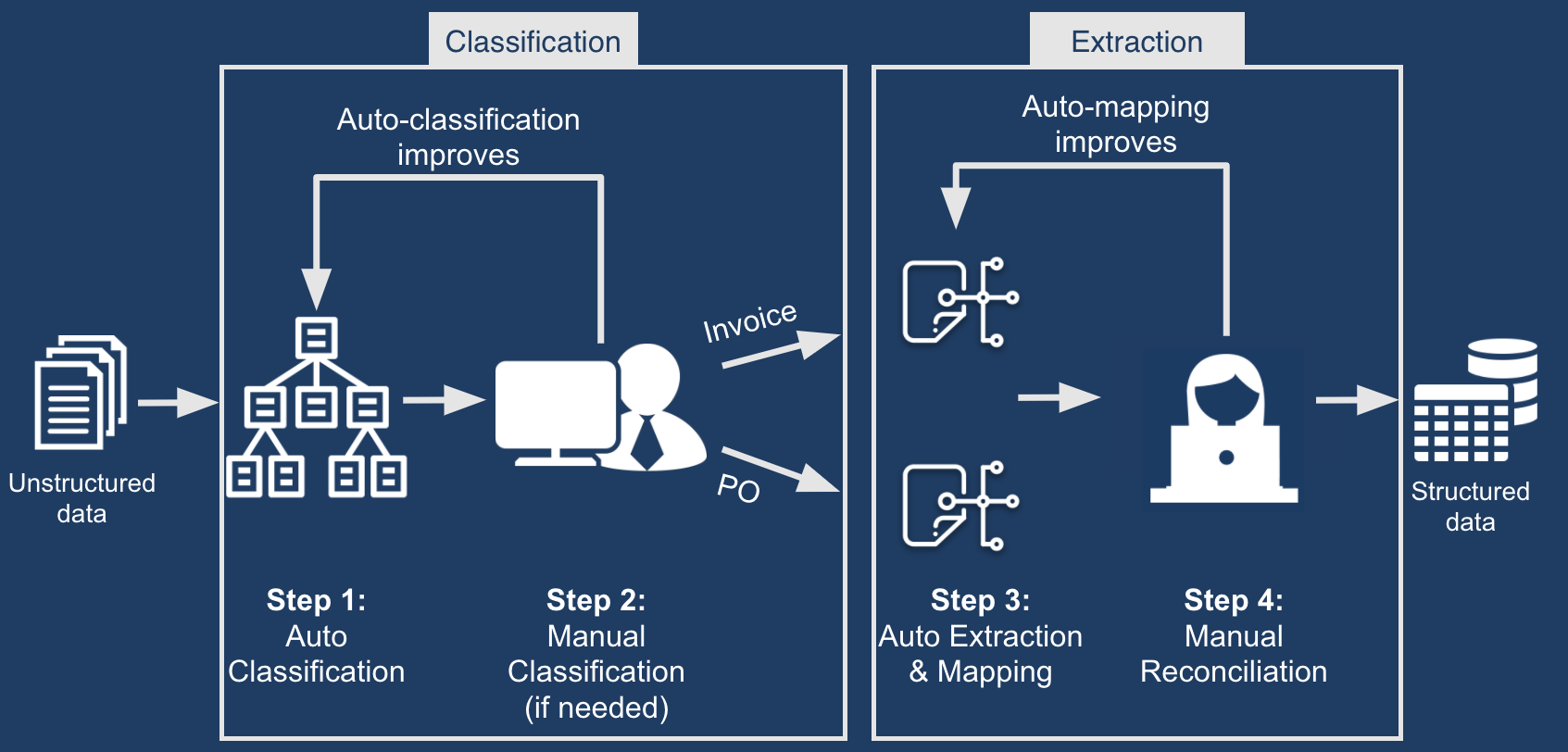
When you upload a PDF file, IDP can automatically classify the document into pre-configured document types. Classifying documents into specific types allows Appian to understand what data to extract. IDP supports claims, invoices, purchase orders, and receipts document types right out of the box.
There are a few ways to classify your documents. When there are multiple document types in a channel, you may classify the documents:
When there is only one document type in a channel, classification can be skipped.
Document channels organize document types into unique security groups so that only authorized users are able to see and interact with their respective documents. IDP has a Standard document channel by default, but you can also add more to suit your needs.
When you classify your documents automatically, and the machine learning (ML) model’s classification confidence is below a pre-set threshold, IDP generates a task for a human to perform the review manually. You want to ensure that these tasks are only assigned to the correct individuals. Use document channels to set unique security for different document types. Once a pre-configured number of documents are manually reviewed, the classification model is automatically retrained to improve future auto-classification activities.
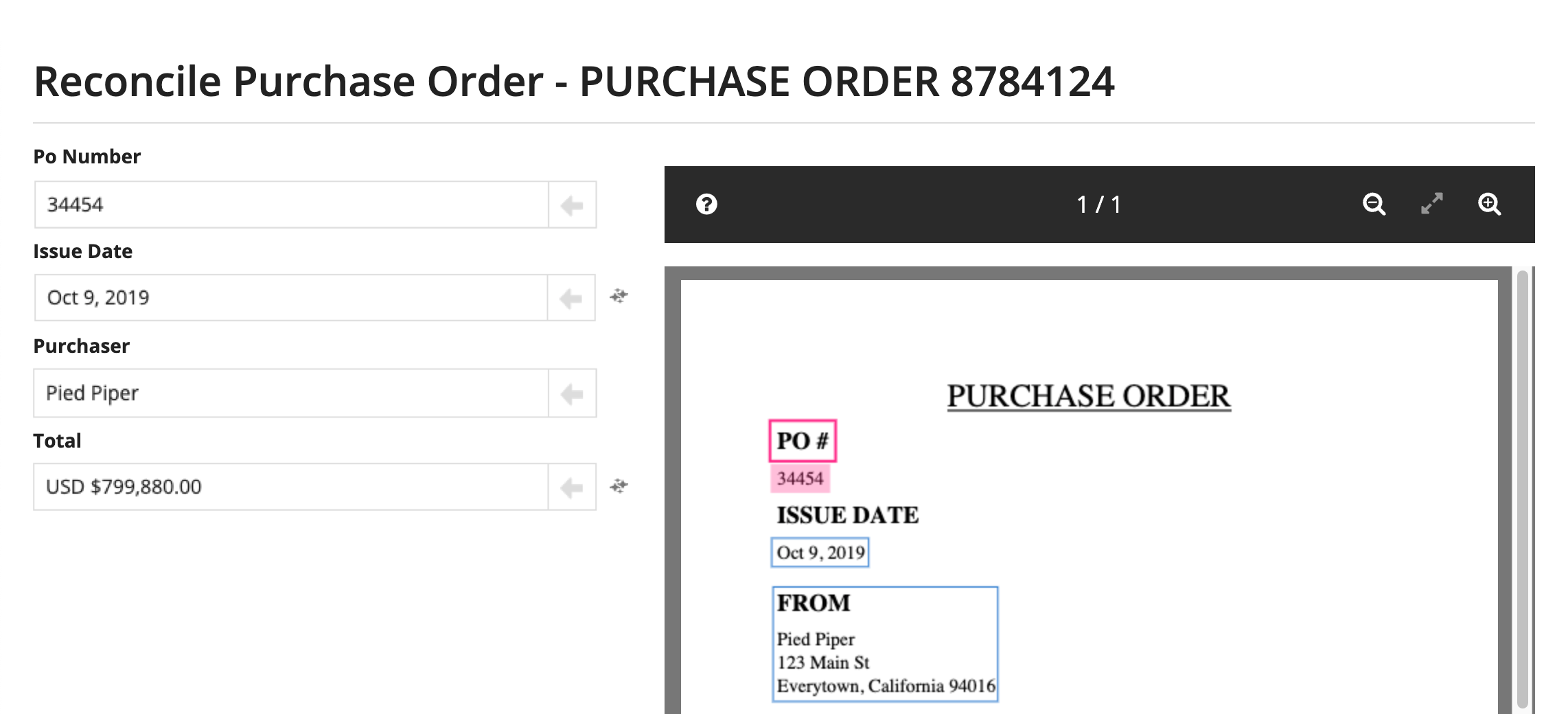
After the document's type is determined through classification, IDP takes advantage of Appian Document Extraction to extract certain fields from the document. For example, for an invoice, IDP extracts the Invoice Number, Invoice Date, Total, and Supplier.
After the data is extracted, a task is created for a user to verify the data and make any necessary corrections. This is referred to as reconciliation. Over time, this process is improved because it uses Appian Document Extraction to learn the different ways the fields can be displayed. For example, it will learn that PO No. and PO # both mean PO Number.
Finally, the once unstructured data is now structured data, stored in a database for further use in applications.
The following graphic illustrates how IDP turns unstructured data into structured data, by first classifying the data and improving the classification model, then extracting the data and improving the results of the extraction.
Data security is important. We want to make sure you understand where your data goes when you use IDP. IDP provides data privacy and protection because it secures your data with Appian as well as Google Cloud.
We've outlined data security practices for all steps in IDP, between Appian and Google systems.
Starting with version 20.1 of Appian, if you are a new Appian customer you are pretty much ready to go. The application is preinstalled on your cloud site. Check out Updating a pre-installed application for the few steps you will have to follow to use your Google Cloud values on your Appian instance.
If you are a self-managed customer with version 20.1 (or higher) of Appian, or if you are an existing cloud customer upgrading to version 20.1 (or higher), you will need to follow these steps to install the application.
After you have customized the application to suit your needs, run through the guided configuration to start training the classification model right away.
After your application is configured, see our Intelligent Document Processing User Guide to learn more about how to:
We wanted to give you the power to get started quickly. So out of the box we offer four document types that are already configured to classify and extract data: invoices, purchase orders, claims, and receipts.
Want to capture different fields from these documents or need a different document type? Appian makes it easy to extend the application to modify the fields that are being extracted for each document type or add more document types.
If your organization needs to process documents from multiple channels, you can add new document channels. For example, if you process documents from the email inboxes of both the Finance and Legal departments, each department likely uses different document types. Moreover, these documents presumably only need to be viewed by their respective teams. This would be a good use case for adding multiple document channels.
You can use IDP directly in the Intelligent Document Processing site. However, you can also use IDP in subprocesses to process documents in larger workflows. Furthermore, you can upload documents from other systems, view the status of a document being processed, and get the extracted data through prebuilt web APIs.