If your business spends countless hours extracting data from documents and forms, Appian is here to help. Appian includes a rich set of artificial intelligence (AI) features that accelerate the low-code development of document extraction processes. Leverage the power of AI to minimize repetitive and manual data extraction, and eliminate the need for expensive, high-maintenance optical character recognition (OCR) software.
Any structured and semi-structured PDFs are well-suited for AI-based document extraction. Structured documents follow a fixed layout such as tax and hospital forms. Semi-structured documents contain similar data in a variety of layouts such as invoices, receipts, and utility bills. Unstructured documents, such as legal contracts and emails with free-flowing paragraphs of text, are best supported with other Appian features.
We are so excited for you to start automating your document extraction processes that we offer a pre-built Intelligent Document Processing (IDP) application that supports automatic document classification and extraction, performance monitoring, and secure processing across multiple teams right out of the box. You are ready to begin automating your document-centric processes after a few, simple configuration steps without creating custom process models or interfaces.
You can also choose to build your own document extraction process using the integrated document extraction smart services and functions in the Process Modeler. For more information, see Create a Doc Extraction Process.
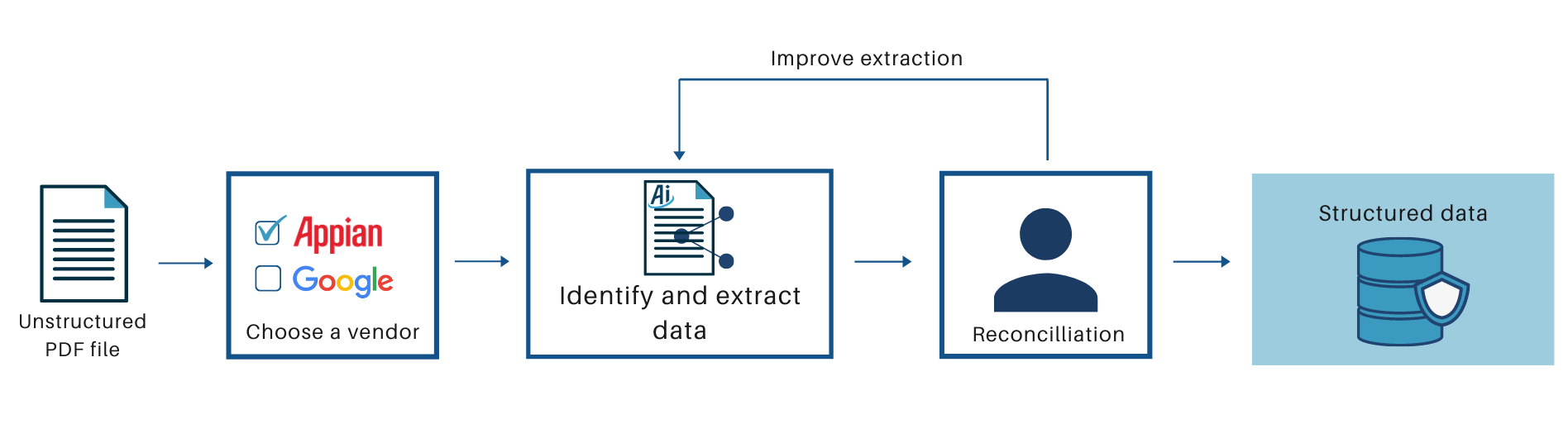
Document extraction identifies data relationships within a PDF document as key-value pairs. For example, an invoice document contains several form fields, so the process will identify the field names and values that are paired together e.g. Invoice Number and INV-12.

Using either Appian's built-in document extraction functionality or Google Cloud Document AI, each key will be mapped to a data type field. This mapping gets smarter over time as you reconcile and correct the extracted data. To reconcile extracted data, Appian auto-generates a form for human-in-the-loop validation of automated extraction results.
After this manual reconciliation, Appian will store and recall the mapping of the extracted key to an Appian field. For example, if you provide mappings, then eventually Appian document extraction will recognize that Invoice Number, Invoice #, and Invoice No. all map to the invoiceNumber Appian data type field.
Document extraction is a powerful tool to use in your business, but before you put in the work to create your own process, think about what you want to do. For example:
If you want the ability to customize these aspects of the document extraction process, like how the data moves post-extraction or who corrects results, you may want to create your own document extraction process. Get started by evaluating document extraction features to use in your process.
If your goal is to extract data and collect insights quickly with minimal to no set up, you may want to use the pre-built Intelligent Document Processing (IDP) application. IDP uses a standardized document extraction process in conjunction with automatic document classification. All you have to do is upload your document.
To take advantage of Appian's full-stack automation features, consider pairing your document extraction process with other Appian AI features and robotic process automation (RPA).
Tip: We want everyone to have access to the power of automation, so we're offering Appian Cloud customers 20,000 pages of document extraction per month included with the platform. This is substantially more than the free offerings of other document extraction vendors.
If your business processes a higher volume of documents, reach out to your account executive to learn about additional pricing options.
We want to make sure you understand where your data goes when you use Appian document extraction features. Document extraction provides data privacy and protection because it secures your data with Appian as well as Google Cloud.
See Data Security in Document Extraction for more information.