
OverviewCopy link to clipboard
For most applications, Appian recommends using record types to build with your enterprise data. When you enable data sync on your record types, you can work with a faster, more flexible version of your data using record type relationships, custom record fields, and other low-code data features.
However, there are some cases where you may need to use custom data types (CDTs) in addition to your record types:
- A record type that does not have data sync enabled, so you need to connect to the source using a data store entity.
- You use a data type plug-in to define a CDT as a Java object.
- Your process model includes an Export Data Store Entity to Excel or Export Data Store Entity to CSV smart service node. Data store entities require a CDT as part of their configuration.
This page will help you understand how CDT relationships work and what factors to consider when defining a data model to meet your business needs.
Data designCopy link to clipboard
Data design is an important part of planning your application. Before creating your CDTs, carefully consider how you want to write data to the database, how you want to use or display your data, and what types of reports you need. CDT design impacts how you query data, and by extension, how your application performs.
Data entities can have more than one level, such as an Employee who has a specific Address. This is represented in Appian by multiple related CDTs.
There are four types of CDT relationships in a data type. Depending on how you will use your data, some CDT relationships work well in a nested design, while others are better suited for a flat design.
The reference table below summarizes Appian's recommendations on how to design your CDTs based on what type of CDT relationship it is.
| CDT Relationship | Recommended Design |
|---|---|
| One-to-One | Nested |
| Many-to-One | Nested |
| One-to-Many | Flat |
| Many-to-Many | Flat |
Nested CDTsCopy link to clipboard
Appian allows you to create nested designs to capture the complex structures of your database. With a nested relationship, data lives in one table but provides context for related table with the use of a foreign key. In Appian, nested relationships are modeled by referencing the child CDT in the parent CDT like the diagram below.
Appian recommends using nested relationships only for one-to-one and many-to-one relationships. One-to-many and many-to-many relationships should be flat to avoid performance issues when querying data.
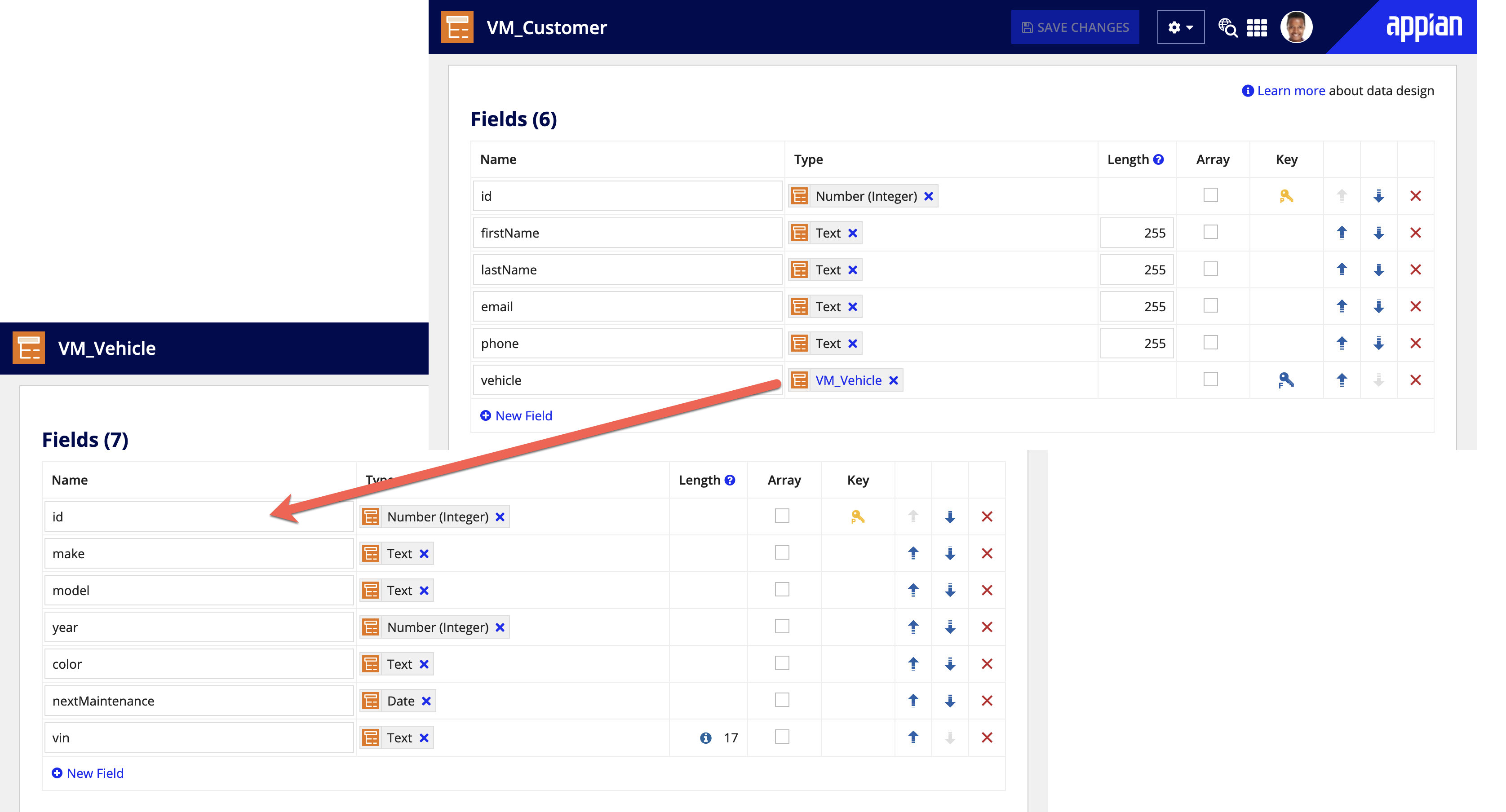

Pros:
- Write one query to retrieve data from multiple tables
- Easy to access all fields of the children when you have a one-to-one or many-to-one relationship
- Easier for reports / charts where you want to display information across the parent and child
Cons:
- Less performant for one-to-many or many-to-many relationships
- Difficult to work with lists of lists when querying multiple rows that contain one-to-many or many-to-many relationships
Tip: It's a best practice to set up a foreign key in your CDT for nested relationships. This is done automatically for you when you allow Appian to generate your database tables.
Flat CDTsCopy link to clipboard
In a flat design, there is no explicit relationship between CDTs in Appian. Neither the parent or child CDT contains the other. Instead, one CDT contains a reference to the other CDT's Primary Key (PK). Therefore, querying one table doesn't return all the fields in the related table, it only returns the primary key.
When a related table is used infrequently, it's better to not build an explicit relationship into your CDTs. If you include the relationship, the related table is automatically queried every time the parent is queried.
When the application needs to return data from related tables, the designer will need to query the related table directly, using the Primary Key values retrieved from the parent CDTs.
Appian recommends making many-to-many and one-to-many relationships flat. If you are currently using or designing a many-to-many or one-to-many CDT, it's best practice to make them independent, but related. Instead of calling another CDT in a CDT Type field, reference the primary key of the related CDT.
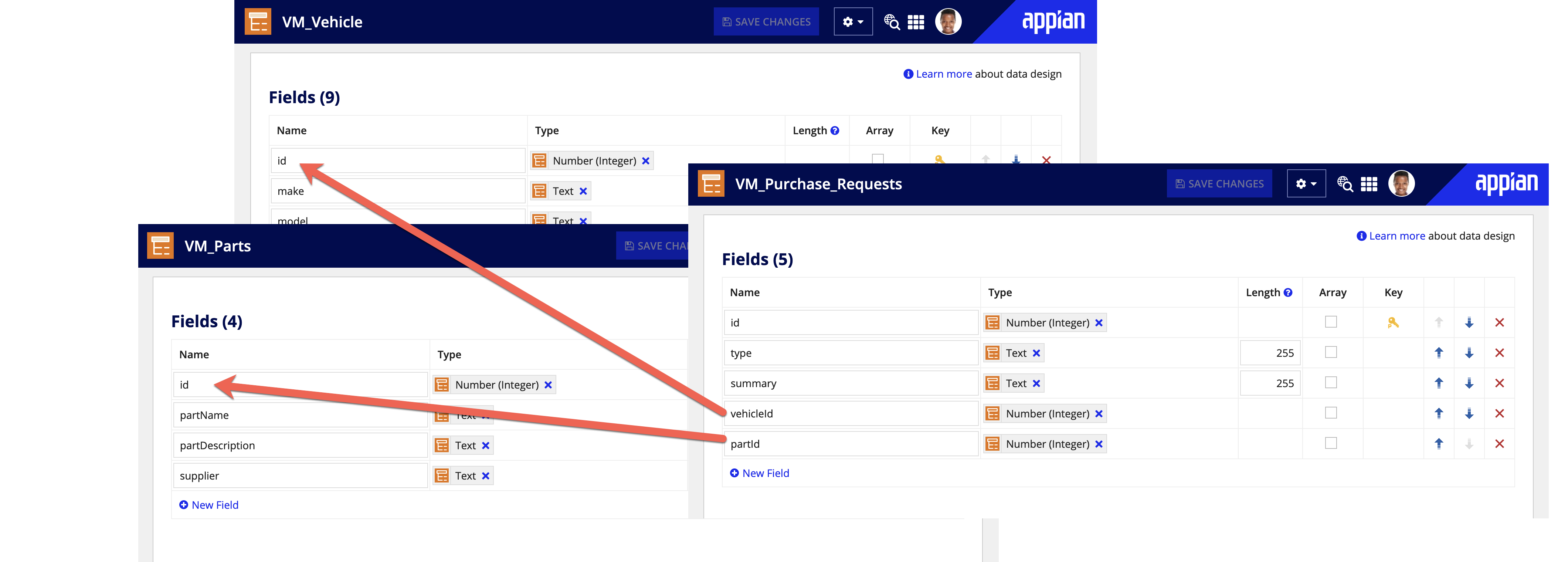
Pros:
- Generally more performant, as you can control/limit the number of queries to your database
- Easier to avoid overwriting concurrent changes since you can write to each table in isolation
Cons:
- Requires creation of additional queries
- Relationships have to be maintained manually
Working with flat relationshipsCopy link to clipboard
This section provides information on how to configure and manage flat relationships.
Configuring flat CDTsCopy link to clipboard
When configuring a flat design, the parent CDT does not contain the child CDT. Instead, either the parent or the child CDT contains a reference to the primary key of the other CDT. Whether the parent or child CDT contains the reference to the other CDT varies based on the relationship type.
The table below summarizes which CDT should contain the reference to either the parent or child CDT for each relationship type, and provides an example of a parent and child relationship.
| CDT Relationship | CDT that Contains the Reference PK | Example |
|---|---|---|
| One-to-One | Parent | Employee (parent), Address (child) |
| Many-to-One | Parent | Order (parent), Status (child) |
| One-to-Many | Child | Case (parent), Comments (child) |
| Many-to-Many | A separate CDT, as explained below | Order (parent), Products (child) |
When using any of the methods below to configure the fields that reference the related CDT(s), your data type should have the following configurations:
- The field name should include the related CDT name and "Id", such as "caseId"
- The field type should be the same as the related CDT's primary key
-
The XSD definition for the field should use the
@JoinColumnannotation, as shown in the example below, where "case_id" is the primary key column on the case table:1 2 3 4 5
<xsd:element name="caseId" nillable="true" type="xsd:int"> <xsd:annotation> <xsd:appinfo source="appian.jpa">@JoinColumn(name="case_id")</xsd:appinfo> </xsd:annotation> </xsd:element>Copy
To configure one-to-one and many-to-one relationships:
- Create the referenced child CDT if it doesn't exist.
- Create or update the parent CDT to add a reference to the child from step 1.
- If using the Create from database table or view option, the reference to the child CDT will be automatically added as long as your database table contains a column for the primary key from the child table. It will already contain the necessary JPA annotations.
- If using the Create from scratch option, you should add the new field directly in your XSD. To do this, download the XSD, add the new field, and upload the new version to update the CDT.
To configure one-to-many relationships:
- Create the referenced parent CDT if it doesn’t exist.
- Create or update the child CDT to add a reference to the parent from step 1.
- If using the Create from database table or view option, the reference to the parent CDT will be automatically added as long as your database table contains a column for the primary key from the parent table. It will already contain the necessary JPA annotations.
- If using the Create from scratch option, you should add the new field directly in your XSD. To do this, download the XSD, add the new field, and upload the new version to update the CDT.
To configure many-to-many relationships:
- Create both the parent and child CDTs if they don't exist.
- Create a third CDT with references to the other two CDTs.
- If using the Create from database table or view option, choose the table that is being used as the join table between the parent and child.
- If using the Create from scratch option, add the following fields to your CDT:
- A primary key.
- A field that corresponds to the primary key of the parent CDT.
- A field that corresponds to the primary key of the child CDT.
- A field that stores the index. This represents the order the children should be returned.
- Update the fields that reference the other two CDTs by downloading the XSDs, adding the necessary JPA annotations, and creating a new version of the CDT from the XSD.
You must add the new fields and configure the JPA annotations before creating and/or publishing the data store. Appian only reads JPA annotations when creating a table or column. Existing columns are never updated based on JPA annotations.
Writing to data storeCopy link to clipboard
Using a flat design can affect the way you write values to the database through a data store entity. For example, when inserting new rows in the database, you may need to write to the data store entities in a specific order because of dependencies.
Master-detail relationshipsCopy link to clipboard
Most one-to-one and one-to-many relationships are master-detail relationships, which means the child CDT is an extension of the parent CDT. The child CDT values are usually created or updated at the same time as the parent CDT values. Because of this, the referenced CDT value may not exist when writing the other CDT value for the first time.
For example, when you have an employee CDT that references an address CDT, the address for that employee doesn’t exist yet when you write an employee to the database for the first time. This means you can’t associate the two rows if you write the employee value first. When this happens, you need to write the referenced CDT value (in this case, the address) to the database first before writing the other CDT (the employee).
To write both values to the database for the first time:
- In a process model, configure the first Write to Data Store Entity smart service to write to the referenced CDT value first.
- For one-to-one and many-to-one relationships, the CDT is the child
- For one-to-many relationships, the CDT is the parent
- In the Data tab, save the Stored Values into a process variable. This will allow you to use the id of the referenced table in step 3.
- Add a Script Task after the Write to Data Store Entity smart service and save the id from the stored value into the corresponding field in your other CDT.
- Add a second Write to Data Store Entity smart service after the Script Task to save the second CDT value.
The result should look like this:
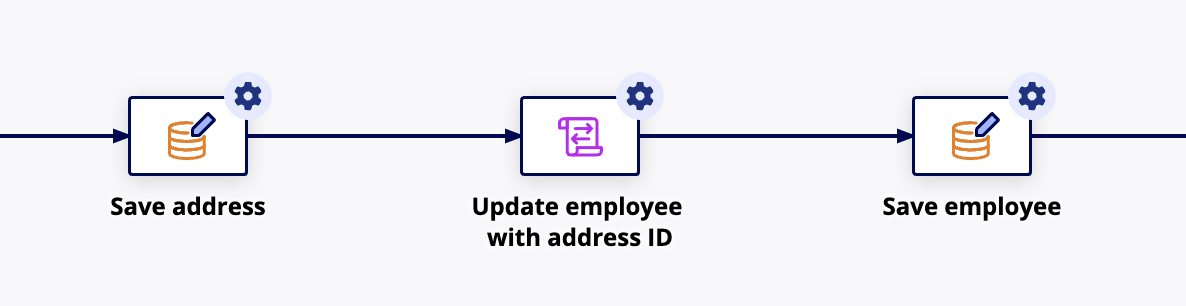
Note: Because multiple smart services are required to write both values for the first time, you cannot use the Write to Data Store Entity smart service function from an interface or Web API. Instead, you must use the Start Process smart service function in order to execute multiple smart services.
This is only necessary when writing the referenced CDT for the first time, to create the data. If the referenced value already exists, you can use a single Write to Data Store Entity node if only updating one of the CDTs or the Write to Multiple Data Store Entities node if updating both CDTs.
Reference relationshipsCopy link to clipboard
The majority of many-to-one and many-to-many relationships are "reference" or "lookup" relationships, which means you "lookup" values from the referenced CDT. These values are managed separately and are rarely created or updated at the same time as the parent CDT. Because of this, the child CDT will usually already exist when you go to write the parent CDT to the database. If for some reason the child CDT doesn't exist when writing to the parent CDT, you'll need to create the child CDT value(s) first before writing to the CDT that references them.
For example, an order CDT that references a product CDT will have a lookup list of products that must exist before someone can create an order containing them.
For many-to-one relationships, you can simply save the id of the child into the parent CDT when writing values to the database. For many-to-many relationships, you'll need to write the parent CDT to the database before writing values to the third CDT that defines the relationship.
To write the parent CDT to the database before writing values to a separate CDT:
- In a process model, configure the first Write To Data Store Entity smart service to write the parent CDT value first.
- In the Data tab, save the Stored Values into a process variable. This allows you to reference the id of the parent CDT in the next step.
- Add a Script Task to generate the values for the mapping CDT. Use an expression similar to the following to generate these values:
1 2 3 4 5 6 7 8 9 10
a!foreach( items: pv!productsForOrder, expression: type!ProductsForOrder( orderId: pv!order.id, productId: fv!item.id, index: fv!index ) )
Copy - Add a Write to Data Store Entity smart service and write the values for the relationship CDT.
The result should look like this:
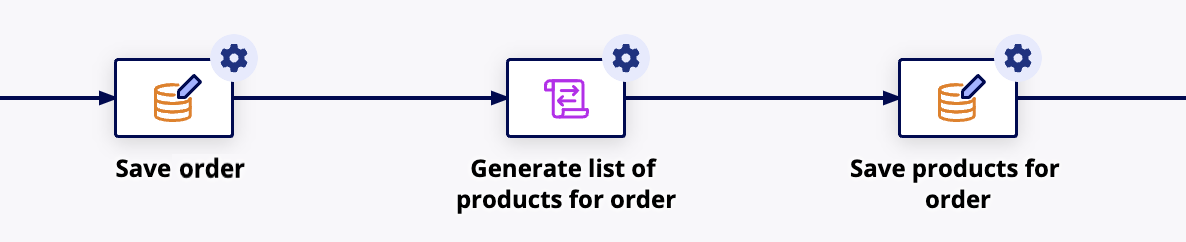
Note: Because multiple smart services are required to write both values for the first time, you cannot use the Write to Data Store Entity smart service from an interface or Web API. Instead, you must use the Start Process smart service in order to execute multiple smart services.
Querying values from the databaseCopy link to clipboard
Using a flat design also means that you will need to write multiple queries in order to retrieve the information from the database. The number of queries will depend on the type of relationship and how many values you need to retrieve. It is important to minimize the number of queries you create in order to have the best performance.
Querying all children for one parentCopy link to clipboard
When viewing a single parent on a record view or in a master-detail, you need one query for the parent and then one query for each of the child relationships. Many-to-many relationships will require an additional query (one for the relationship table itself). Each of these queries can be individually configured using the query editor in an expression rule.
The expression below queries all children for one parent using the example of orders with a status (many-to-one) and products (many-to-many):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
a!localVariables(
/* Query the parent */
local!order: a!queryEntity(
entity: cons!ORDER_ENTITY,
query: a!query(
filter: a!queryFilter("id", "=", ri!orderId),
pagingInfo: a!pagingInfo(1, 1)
)
).data,
/* Query the many-to-one child */
local!status: a!queryEntity(
entity: cons!ORDER_STATUS_ENTITY,
query: a!query(
filter: a!queryFilter("id", "=", local!order.statusId),
pagingInfo: a!pagingInfo(1, 1)
)
).data,
/* Query to get the many-to-many child ids */
local!productIds: index(a!queryEntity(
entity: cons!PRODUCTS_FOR_ORDER_ENTITY,
query: a!query(
/* You don't need all columns, just the ids */
selection: a!querySelection({
a!queryColumn("productId")
}),
filter: a!queryFilter("orderId", "=", ri!orderId),
pagingInfo: a!pagingInfo(1, -1, a!sortInfo("order", true))
)
).data, "productId", {}),
/* Query to get the many-to-many children */
local!products: a!queryEntity(
entity: cons!PRODUCT_ENTITY,
query: a!query(
filter: a!queryFilter("id", "in", local!productIds),
pagingInfo: a!pagingInfo(1, -1)
)
).data,
...
)
Copy
Querying children for multiple parentsCopy link to clipboard
When viewing a report with many parent values, you should use one query for the parent and then one query for each of the child relationships. Many-to-many relationships will require an additional query (one for the relationship table and then one to retrieve the child values). You then need to map the child values to each of the parents.
The expression below queries children for multiple parents using the example of orders with a status (many-to-one) and products (many-to-many):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
a!localVariables(
local!pagingInfo: a!pagingInfo(1, 25),
/* Query the parent array */
local!orders: a!queryEntity(
entity: cons!ORDER_ENTITY,
query: a!query(pagingInfo: local!pagingInfo)
),
local!uniqueStatusIds: union(index(local!orders.data, "statusId", {}), {}),
/* Query the many-to-one children */
local!statuses: a!queryEntity(
entity: cons!ORDER_STATUS_ENTITY,
query: a!query(
filter: a!queryFilter("id", "in", local!uniqueStatusIds),
pagingInfo: a!pagingInfo(1, -1)
)
).data,
/* Query to get the many-to-many children relationships */
local!productsForOrders: a!queryEntity(
entity: cons!PRODUCTS_FOR_ORDER_ENTITY,
query: a!query(
filter: a!queryFilter("orderId", "in", local!orders.id),
pagingInfo: a!pagingInfo(1, -1, a!sortInfo("order", true))
)
).data,
local!uniqueProductIds: union(index(local!productsForOrders, "productId", {}), {}),
/* Query to get the many-to-many children */
local!products: a!queryEntity(
entity: cons!PRODUCT_ENTITY,
query: a!query(
filter: a!queryFilter("id", "in", local!uniqueProductIds),
pagingInfo: a!pagingInfo(1, -1)
)
).data,
/* Match up the parent and child values */
local!ordersWithChildren: a!foreach(
items: local!orders,
expression: a!localVariables(
local!productIds: index(
local!productsForOrders.productId,
wherecontains(fv!item.id, tointeger(local!productsForOrders.orderId)),
{}
),
{
order: fv!item,
status: displayvalue(
fv!item.statusId,
local!statuses.id,
local!statuses,
null
),
/* Flatten the list of products for each order into one string for display purposes */
productNames: joinarray(
index(
local!products.name,
wherecontains(local!productIds, local!products.id),
{}
),
", "
)
}
)
),
a!gridField(
label: "Orders",
data: local!ordersWithChildren,
columns: {
a!gridColumn(
label: "Description",
value: reduce(fn!index(_, _, {}), fv!row, {"order", "description"}),
),
a!gridColumn(
label: "Status",
value: reduce(fn!index(_, _, {}), fv!row, {"status", "name"})
),
a!gridColumn(
label: "Products",
value: index(fv!row, "productNames", {})
)
},
validations: {}
)
)
Copy