
| A guided, low-code experience for document extraction is here! AI skills are a faster and simpler way to classify documents and extract data from them. |
IntroductionCopy link to clipboard
Before you begin integrating document extraction into your business processes, it's important to evaluate whether Appian's features are a good choice for the documents you work with.
This page covers what makes a document either a good or bad candidate for document extraction. Where possible, we offer additional guidance to help you find a solution to process your documents using Appian. Follow the steps below to determine if your documents would be a good fit for Appian document extraction.
Step 1: Determine your document's digitization statusCopy link to clipboard
Appian is capable of processing PDF documents up to 15 pages or 7 MB. In the context of Appian document extraction, there are three types of PDFs that can be processed:
- Flattened PDF: No text data associated with the file. It doesn't contain digital text or form fields. Often, these types of PDFs are created from paper documents that have been scanned.
- Searchable PDF: Contains digital text data that can be highlighted, copied, searched, and accessed programmatically. This type of PDF has undergone previous processing or was saved from a word processor.
- Fillable PDF: Similar to a searchable PDF, this file allows the user to input and save additional information into form fields.
If you know which category your document falls into, it can help you later on when choosing a vendor to process the document. However, knowing the digitization status isn't necessary, as Appian is able to process most data in all three of these statuses.
Step 2: Determine your document structureCopy link to clipboard
The digitization status and format of your documents will ultimately determine how much data Appian can successfully extract from them. Before we dive into the specifics, first consider the structure your documents contain. Documents vary by how the content is organized, so you may find it helpful to have a few examples to reference as you evaluate.
Structured data includes information that's arranged in a fixed layout. Tax forms, passport applications, and hospital forms are good examples of documents with structured data. Appian can extract data from these types of documents easily due to the predictable and consistent positions of labels and values. Appian can use field position to learn more about your data and improve extraction results. To help train the feature, you can use consistently structured documents that place the same fields in the same places. As you complete reconciliation tasks, the feature learns to recognize data based on its position.
Here is an example of a structured document:

Tip: When you get ready to implement document extraction in your processes, you can use the IsStructuredDoc input in the Reconcile Doc Extraction smart service to use position to improve data recognition and extraction.
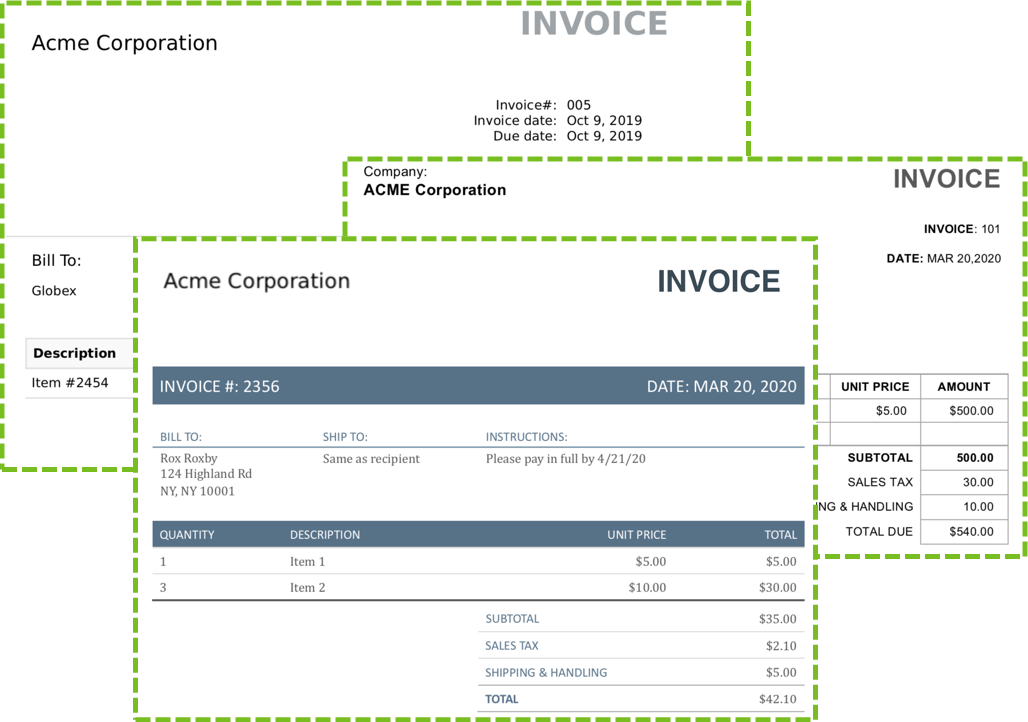
Semi-structured data includes similar pieces of information, but in varying layouts. Invoices, receipts, and utility bills are good examples of documents with semi-structured data. Appian's document extraction features are well equipped to identify and extract semi-structured data. Automatic extraction improves as you process additional documents.
Here is an example of a semi-structured document:

Unstructured data includes free-flowing paragraphs of text. Legal contracts and emails often include unstructured data. This type of information is more difficult to extract because the machine learning algorithms that identify the information are looking for key-value pairs. Larger blocks of text, or parts of that text, are more difficult to extract.
Here is an example of an unstructured document:

If your documents contain unstructured data, you may still be able to extract data from them:
- If you'd like to get text out of a document, we recommend using the Google Cloud Vision Connected System or the PDF Tools plug-in.
- If you'd like to execute rule-based actions to find the desired text in a document, we recommend using Appian expressions or the Regular Expression Functions plug-in.
Step 3: Evaluate the document's contentCopy link to clipboard
Documents with these traits make good candidates for Appian's suite of doc extraction features:
Documents with similar information. For example, invoices that all have invoice numbers and totals.
Documents with clearly labeled values. When the data is extracted, Appian pairs these labels with their corresponding values. For example, the date label and March 1, 2021 value.
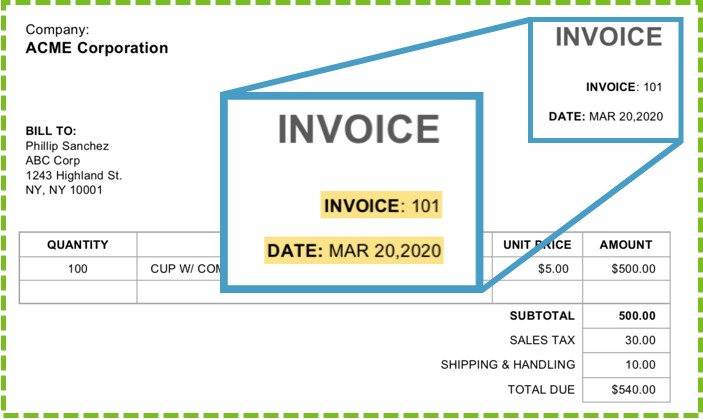
Documents with tables. Tables are another way to structure data in invoices and other documents with line items.

Documents in supported languages. Appian can extract data from documents in the following languages. Additional languages may be supported for documents with a digital layer (not flattened PDFs, i.e. scanned documents). Google's Document AI service also supports additional languages.
- English
- French
- German
- Italian
- Polish
- Portuguese
- Spanish
- Swedish
Does your document sound like a good fit so far? Great! Before you get started, also be sure to consider which documents might not be a good fit. We want to make sure you get the most value from Appian document extraction, and identifying which documents won't work is equally as important as identifying the documents that will.
If your document isn't a good fitCopy link to clipboard
Since Appian Document Extraction is meant to extract labels and values, extracting paragraphs of text is not a good use case for it. If you need to extract paragraphs of text, try using the Google Cloud Vision Connected System.

Likewise, if you need to find specific information in text, such as footnotes in a document, you will be better served by the Google Cloud Vision Connected System along with expressions to analyze the output.

Step 4: Choose the best vendor for your documentsCopy link to clipboard
After you've determined Appian can extract data from your documents, the next thing to consider is whether you want to use Appian's built-in capabilities or supplement them with Google's services. Both vendors provide strict data privacy and protection, but if your business requires you to keep data within Appian, you have the option to choose which vendor processes the documents.
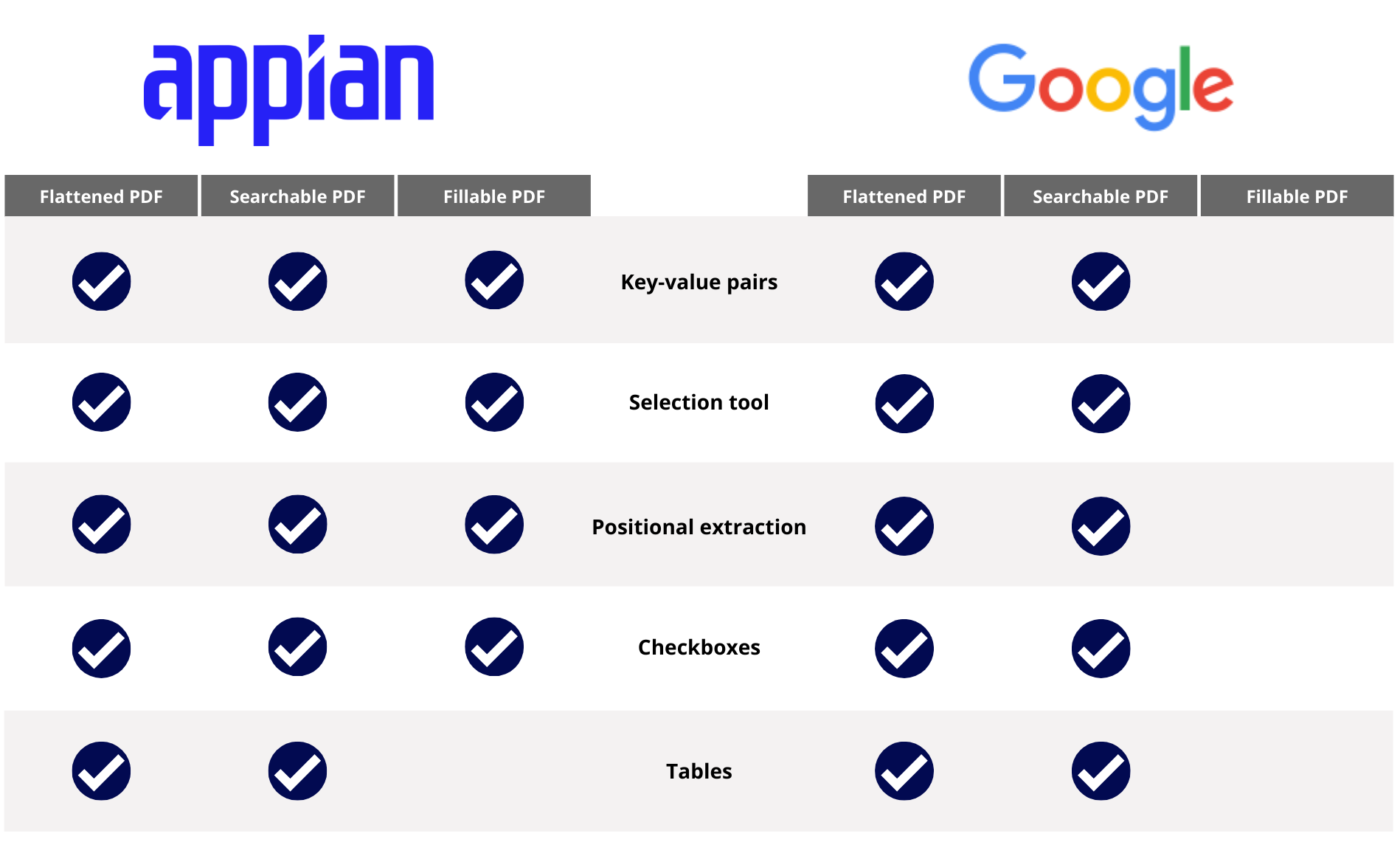
So, which vendor is the best fit? As shown in the table below, both Appian and Google are capable of extracting data from flattened PDFs and searchable PDFs. Appian automatically extracts data from fillable PDFs regardless of the vendor you choose.
Refer to the table below to see which vendor supports certain data extraction processes and tools based on the type of data being processed:
- Key-value pairs: Identify and extract labeled values in documents.
- Selection tool: Use Appian's selection tool in the reconcile interface to manually select the values to extract.
- Positional extraction: Extract values from documents that follow a template.
- Checkboxes: Extract values from checkboxes.
- Tables: Extract information from tables.

Because both vendors offer comparable capabilities, the decision comes down to preference or requirements, such as:
- Keeping your data within your Appian environment. If your industry, compliance requirements, or other business standards require you to keep data within Appian, choose Appian as your document extraction vendor.
- Ease of getting started. If you want to get started with document extraction today, choose Appian as your vendor. You won't need to go through additional steps to get set up.
- Processing documents that contain a lot of handwriting. For example, scanned applications or other types of forms. If you need to extract handwriting to save it as a string, you can use Appian as your vendor. Google's document extraction services are also well equipped to handle documents with handwriting.
Tip: Some customers may need to opt in to Appian's enhanced optical character recognition (OCR) service to process documents with handwriting, noisy, or skewed data.
Appian's servicesCopy link to clipboard
Extraction of different data types from the following types of PDFs are supported when Appian is selected as the vendor:
- Flattened PDFs: Key-value pair extraction, the selection tool, positional extraction, checkbox extraction, and tables.
- Searchable PDFs: Key-value pair extraction, the selection tool, positional extraction, checkbox extraction, and tables.
- Fillable PDFs: Key-value pair extraction, the selection tool, positional extraction, and checkbox extraction.
Tip: Appian's built-in document extraction capabilities related to flattened PDFs, key-value pair extraction, and table extraction are only available for Cloud customers at this time. Self-managed and Appian Gov Cloud customers don't have access to these features. Other built-in capabilities are available for both Cloud and self-managed customers.
Google's servicesCopy link to clipboard
Extraction of different data types from the following types of PDFs are supported when Google is selected as the vendor:
- Flattened PDFs: Key-value pair extraction, the selection tool, positional extraction, checkbox extraction, and table extraction.
- Searchable PDFs: Key-value pair extraction, the selection tool, positional extraction, checkbox extraction, and table extraction.
- Fillable PDFs: Processed automatically on your Appian environment.
Note that Appian's built-in document extraction capabilities automatically handle fillable PDFs, regardless of the vendor you select. To use Google for all of your forms, including fillable forms, flatten your PDFs before beginning extraction. For example, you can add the Community supported PDF Tools plug-in in your process model to flatten PDFs before the extraction nodes.
Step 5: Try it out!Copy link to clipboard
Appian offers low-code objects and built-in services to help you harness the power of artificial intelligence (AI) to extract data from your documents. Learn how to create a document extraction process.