| A guided, low-code experience for document extraction is here! AI skills are a faster and simpler way to classify documents and extract data from them. |
Appian includes a rich set of low-code, artificial intelligence (AI) features that accelerate the development of document extraction processes. As always, we continue to support automated extraction from a wide range of documents. Depending on your specific use cases, you may choose to power the document extraction with built-in Appian services or with Google Cloud Document AI technologies. Either way, your document extraction is done from within Appian. Let's look at some industry examples to see how document extraction can best fit the needs of your organization:
- Invoices and purchase order processing
- Consumer banking forms processing
- Hand-written insurance claims processing
- Identification documents processing
Invoices and purchase orders processingCopy link to clipboard
Suggested Vendor: Appian or Google
Invoice and purchase order (PO) processing is essential for businesses across nearly all industries. As organizations scale, processing invoice and PO documents manually can quickly become a bottleneck for other workflows.
Let's say your Appian application supports a rapidly growing finance department. You have a limited number of employees, and they increasingly spend an overwhelming amount of time processing invoices and POs each day. Building AI-based document extraction into your existing Appian workflows can take the burden off your employees, freeing them up for more meaningful tasks. Not only does AI take these tasks off your employees' plates, but AI performs these tasks far more quickly and accurately.
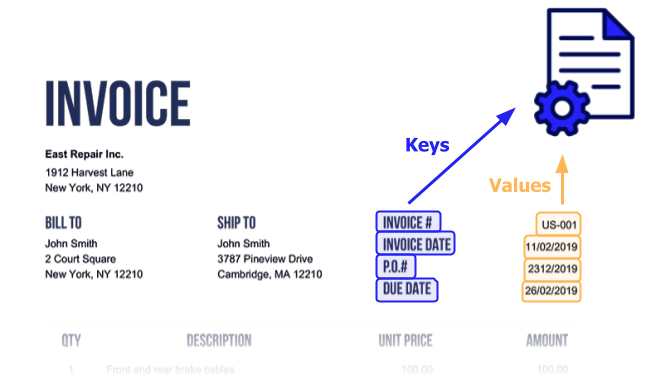
Invoice and purchase order document types are a great fit for automatic document extraction because they contain semi-structured data. As shown in the example below, this document type contains clearly labeled values that are easily extracted into key-value pairs. In this scenario, Appian or Google are both suitable vendors for AI-based document extraction.
Consumer banking forms processingCopy link to clipboard
Suggested Vendor: Appian
When working with sensitive financial documents at a bank, security is of the utmost importance. Yet, you most likely still process many forms manually on paper without a digital workflow. Because you often process thousands of these documents a week, these processes are error-prone and time consuming. You may already be using Appian to enhance your other workflows, so how can you take it one step further?
We recommend using built-in Appian document extraction to process your secure documents. While Google still remains a suitable choice, using the built-in document extraction keeps all of your data within Appian Cloud.
Hand-written insurance claims processingCopy link to clipboard
Suggested Vendor: Appian or Google
Your application receives hundreds of hand-written insurance claims a day, and your team is overwhelmed by the amount of claims data. Manual processes are slowing you down and increasing the possibility of errors. You may not think it is possible to automate data extraction from hand-filled documents, but Appian or Google can accurately extract meaningful data from these document types.
What's more, when you work with an Appian application, you are supported by a full suite of low-code automation products. For example, you can enhance your processes even further by intelligently sending claims to the adjusters on your team to review customers' medical records using natural language processing in addition to document extraction.
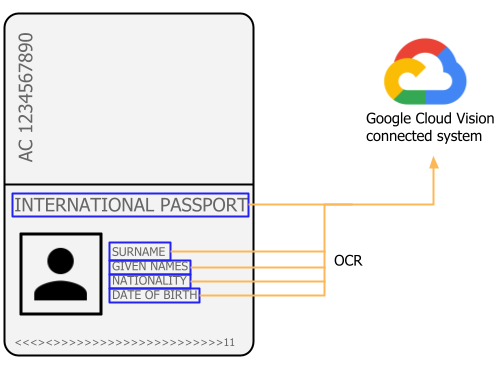
Identification documents processingCopy link to clipboard
Suggested Vendor: Google
Your travel agency's application needs a way to quickly process customers' passports. This process has been difficult to streamline because employees have to copy and verify customer information quickly, while maintaining a high level of accuracy for the sake of compliance. Your business serves a rapidly growing customer base, and this adds to the complexity of your process. Oftentimes, a front-desk worker must call a manager to help review the passports in a timely fashion.
Processing identification documents is a common scenario that is best supported with optical character recognition (OCR) and rules-based extraction. This is because these documents often do not have key-value pairs for built-in Appian document extraction to recognize. To set up a document extraction process for these document types, we recommend using the Google Cloud Vision connected system and configuring expression rules for the extraction.
Building OCR and rules-based extraction into your existing workflows will allow you to quickly and easily extract relevant data from identification documents, as well as make it even easier to automate extra review activities you may need to perform.