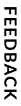Appian's data service is our custom-built data and analytics engine designed to handle both OLTP and OLAP workloads. The architecture of the data service guarantees ACID-compliant transactions while also offering predictable performance across a variety of use cases. Data for record types with sync enabled is stored in the data service, along with other application data and metadata, including user-saved filters for a record list or records-powered grid.
The distributed architecture of the data service creates a fault-tolerant database service, significantly improving the reliability of reads and writes. The data service consists of the following:
The historical store (or hs) component executes write requests to the data service. This component consists of a gateway that listens for write requests from the application server and an engine that ensures a given write request is valid. After a write request has been validated, the historical store commits the transaction by forwarding the request to the Internal Messaging Service, which serves as a transaction log for the data service.
The effects of a new transaction are distributed from the Internal Messaging Service to each component of the data service, and are periodically appended to the immutable kdb+ database that underlies the historical store. If the component fails before data has been appended to the aforementioned kdb+ database, the historical store achieves its durability guarantees by replaying transactions upon startup from the Internal Messaging Service transaction log.
Note: The data service depends on a running instance of the Internal Messaging Service for write transactions to be committed. If the Internal Messaging Service is unavailable, writes to the data service will fail.
Each real-time store (or rts) component processes and executes query requests to the data service. When query requests are made from the application server, they are load-balanced across the real-time stores.
Each real-time store component consists of a gateway that listens for query requests from the application server and an engine that serves the query request and provides the requested data. All real-time stores share an underlying kdb+ database, called the snapshot database, that is optimized for query performance. This database is generated periodically by the appender component.
For Appian Cloud, the default number of real-time stores varies based on the amount of memory available on each node as shown below.
| Available Memory | Default RTS Count |
|---|---|
| Less than 32GB | 2 |
| Between 32GB - 127GB | 4 |
| Between 128GB - 384GB | 8 |
| Greater than or equal to 384GB | 12 |
Note: If queries to your synced record types become slow during peak user load, you can increase the number of real-time stores to support higher query throughput. However, the number of real-time stores will depend on your site's available memory and CPU resources. Open a support case for more information and to see if you are eligible for an increase.
Self-managed customers who have the data service configured to run with only two real-time stores should review the guidelines for provisioning the rts-count property specified in the appian-topology.xml file.
The appender component performs all background operations in the data service. This includes periodically appending data from memory to the historical store database, generating a new snapshot database to be used by the real-time store components, and performing garbage collection. This component consists of a gateway that schedules and initiates each background operation and an engine that executes each background operation.
The data client runs in the application server. It provides a simple interface for the rest of Appian to communicate with the data service.
The watchdog component runs a Java process that monitors the health of each data service component. In the event of an isolated failure of any other component, the watchdog will attempt to heal the failed component. If the watchdog component itself fails, it will self-heal.
To configure the data service, you need to have a valid license and a security token before you can configure the data service in appian-topology.xml.
A valid license (k4.lic) is required to run the data service. See Requesting and Installing a License for information on obtaining and installing a k4.lic license.
Requests to the data service are secured with a security token that's unique to every customer environment:
If the token has not been set properly, the data service will not start, which will result in the application server not starting. See Data Service Connection Restrictions for more information.
The data service topology is specified in the appian-topology.xml file. See Configuring the Data Service for more infomation.
Note: In order to start the data service, the appian-toplogy.xml file must be identical in both the <APPIAN_HOME>/conf/ directory and the <APPIAN_HOME>/data-server/conf/ directory. If these two files are not in sync, then the data service will fail to start.
The <APPIAN_HOME>/ae/data-server/ directory stores the data service binaries, scripts, configuration details, and data.
The data files are located in the <APPIAN_HOME>/ae/data-server/data/ directory. The hs directory contains the historical store database files and the ss folder contains the snapshot database files. Since access to data service is latency-sensitive, it is recommended that the data is hosted locally on the machine, rather than a shared drive or an external drive, such as shared network-attached storage (NAS). This is true in High Availability (HA) topologies as well, since each data service node stores its own version of the data.
For disaster recovery purposes, the <APPIAN_HOME>/data-server/data/ directory and the Kafka logs should be backed up regularly.
See Internal Data for a comprehensive overview of where Appian persists data on the file system.
Each component of the data service writes its logs to the <APPIAN_HOME>/logs/data-server/ directory:
hs-engine.log and hs-gateway.logrts-engine-*.log and rts-gateway-*.logappender-engine.log and appender-gateway.logclient.logwatchdog.logThe log files contain important information about startup and shutdown, process execution, configuration, and errors. In the event of a system issue, these files should be shared with Appian Support. Note that for the real-time store components, the logs are enumerated as rts-engine-0.log, rts-engine-1.log, etc. for each real-time store component.
Note: The <APPIAN_HOME>/logs/data-server/ directory will always be free of any customer business data, and can be safely exported without any risk of exposing sensitive data.
The data service also logs other data, including performance metrics and traces. See Logging for a more comprehensive overview of Appian logs.
Watchdog continuously monitors each component of the data service and restores functionality of each component in the event of an isolated failure.
To validate that the data service is running correctly, execute the <APPIAN_HOME>/data-server/bin/health.sh script (health.bat on Windows). The following information is displayed after executing the health script:
For the data service cluster:
true if the data service is functioning normally, otherwise false.For each node in the data service cluster:
true if the data service is functioning normally on this node, otherwise false.After configuring the data service, the amount of disk space and memory consumed by the data service will vary.
After it is started for the first time in your environment, the data service may take up to 40MB of disk space by default. If a site is not syncing record data, then additional disk space usage from the data service will be negligible.
If a site is syncing record data, the data service will consume disk space proportional to the total amount of data synced from all sources. As a rough estimate, the data service is expected to consume up to 10 times the total amount of raw data. This occurs as a result of various optimizations, including building indices and creating read-only replicas to improve query performance. The exact disk space consumption will vary depending on the data types of your record fields. For example, syncing data with many large strings will consume significantly more disk space.
Note: In order to perform its internal optimizations on the data, the data service requires sufficient overhead disk-space availability. If there is insufficient disk space available for the data service to run its internal optimizations, queries performance will degrade.
If more space is provisioned or sufficient space is cleared, the data service will resume its background operations without any other intervention required.
All combined, the watchdog, hs-gateway, rts-gateway-0, rts-gateway-1, and appender-gateway processes require approximately 200MB of memory to run. If a site is not syncing record data, then additional memory usage from the data service will be negligible.
If a site is syncing record data, there will be significant spikes in memory usage during the sync. Memory spikes will also occur while complex queries and background operations are running. Under normal workloads, these spikes should not exceed 1GB. In a worst-case scenario, memory spikes could result in spikes up to 4GB. For example, syncing data with excessively large text columns might result in a higher memory spike.
To start or stop the data service, refer to Starting and Stopping Appian.
Tip: When logging out of Windows, the data service process started by the user using the script will stop.
Consider installing the data service as a Windows service and using the Windows Service management console to start and stop the service. For instructions, see Installing the data service as a Windows Service.
If the data service is unreachable when the application starts up or if the application is started before the data service is running, the application server will not start.
If the data service cannot start and the watchdog.log indicates an issue with the security token, see Data Service Connection Restrictions for troubleshooting.
If the data service stops running while the application server is running, you will not be able to access, create, update, or delete user-saved filters. Additionally, any record types with data sync enabled will be temporarily inaccessible. See Troubleshooting Data Sync for more information.
Data Service