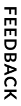| Process Mining is deprecated with Appian 24.2 and will no longer be available in an upcoming release. Instead, we encourage customers to use Process HQ to explore and analyze business processes and data. |
As you prepare to load your data into Mining Prep, you may need to configure some network settings to allow communication from Appian. This step is required before you add a data source and add data sets directly to Mining Prep.
You may also want to review your data for personal identifiable information (PII) or other legally protected information before loading data into Mining Prep. For more information, see Security Considerations.
If you aren't sure how to access Mining Prep for the first time, see Sign In to Process Mining for instructions.
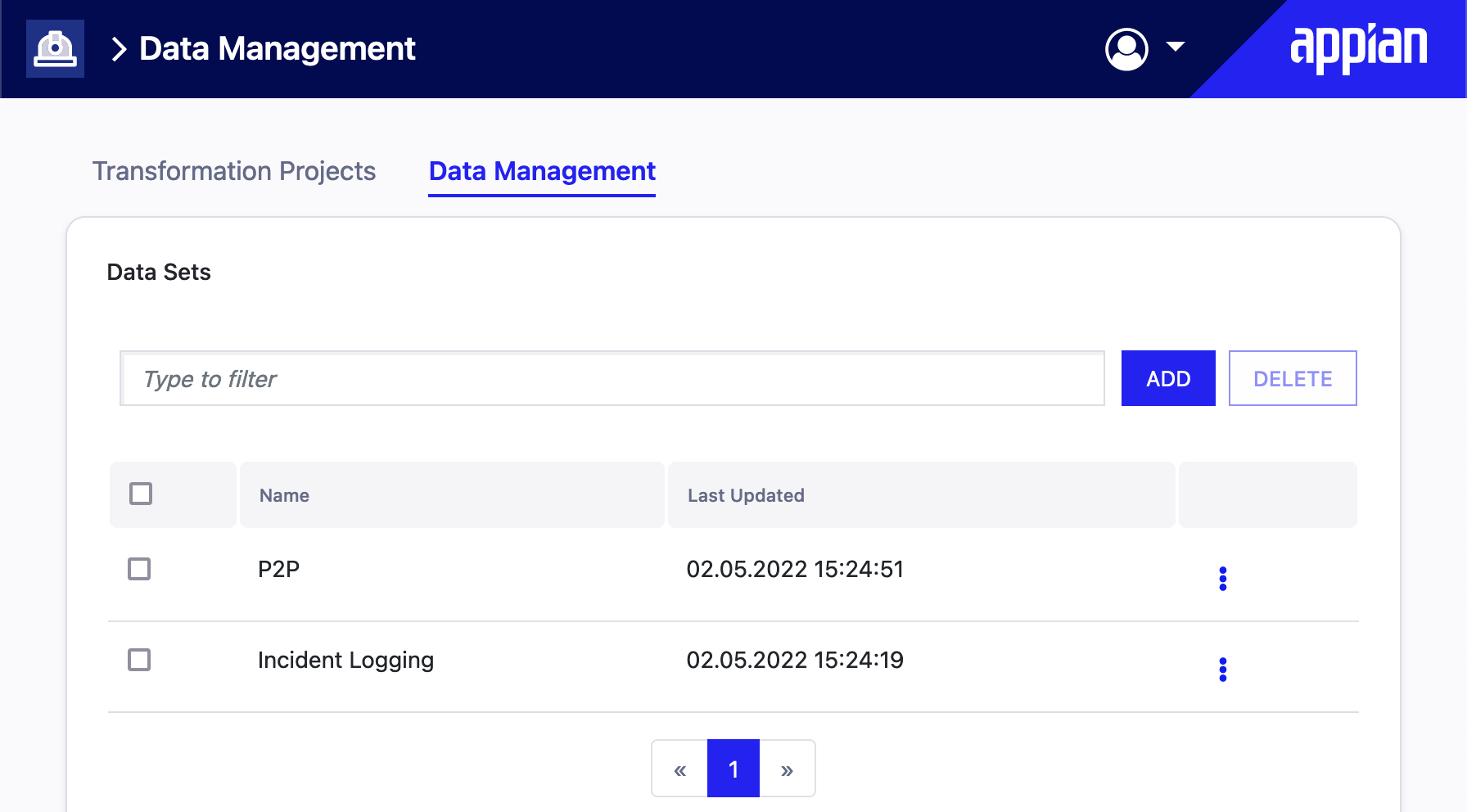
On the Data Management tab, you can add the data you want to transform into an event log for process mining. An event log is a list of events that process mining uses to analyze processes. Events represent activities in process mining. Activities are tasks in a business process that may be automated or performed by a human. They are often associated with start and end time stamps, who performed the activity, or how much the activity cost.
You can either upload the data from a CSV file or connect to another data source like a database or Enterprise Resource Planning (ERP) application.
Note: You can upload a file up to 1 GB in size for Appian Cloud Mining Prep installations depending on your local network speeds.
There are a couple of options to import your data into Process Mining:
The Data Sets section displays all files that you've uploaded to Mining Prep. You can use these files to start a new transformation or add them to an existing transformation. To preview the contents of a data set, click the row it belongs to in the table.
At a basic level, processes with large amounts of relevant data are good candidates for process mining. For example, an automated purchase-to-pay system probably logs an event whenever an invoice is created and another when an invoice is paid. These events are often associated with time stamps and attributes like who initiated the event or the purchase price. A lot of value is hidden in these large data sets, and process mining can help you make sense of it.
The previous example highlights an automated process. Automated processes that record lots of data and are well understood by your organization are great candidates for optimization in Process Mining. That is, you can use Process Mining to compare how your process actually functions against how you expect it to operate.
Unstructured processes that have a lot of available data but aren't well understood by your organization are perfect candidates for discovery. That is, you can use Process Mining to visualize your process for the first time and make sense of how it operates.
In either instance, you'll want to consider some of the characteristics that make these data sets good candidates for process mining. Data sets should include:
In addition to these requirements, it is helpful to also include case and event attributes in your data sets.
It is a good idea to include these attributes in your data sets because they are available as filters in Process Mining. Additionally, this extra information can help you make observations such as how costly a deviation or variant is in your process.
The last area to consider is what period of time to include in your data set. This depends heavily on your specific process and process mining goals. For example some processes may complete within a single week, and others may complete within several months.
It is generally a good practice to select a timeframe that allows for at least a few cases to fully start and complete. When in doubt, it is always better to include more data, as this offers more analysis opportunities. Even if you import a larger timeframe than is necessary, there are options to refine and filter the data to suit your specific goals.
The following image shows a potential data set that includes all of the requirements for process mining analysis.
Before you upload a data set, make sure the file conforms with these standards:
To upload a data set from a local CSV file:
Tip: If your data is in an Excel spreadsheet, you can save your sheets as CSV files from the Save As menu in Excel.
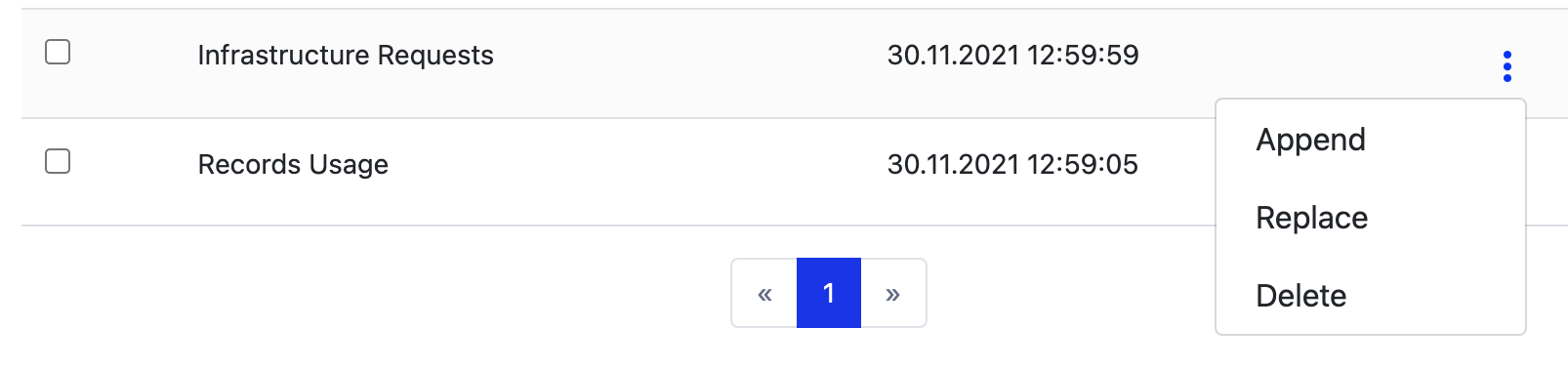
If you need to update data sets that you've already uploaded, you can either append or replace the file:
Mining Prep expects the same column headers as the original file when you append or replace. When you append or replace a data set, all of your transformations that rely on that data set will automatically use the new data the next time the Mining Prep executes the transformation.
If you don't want to append or replace, you can also delete and re-upload the file as a new data set.
In addition to uploading CSV files, Mining Prep can import data sets from a database or ERP application. Standard connectors come out of the box for the following systems:
To connect Mining Prep to a data source, you need to allow network traffic from Appian Cloud. Self-managed installations don't need to complete this step.
To connect to a supported data source:
If you do not know the necessary credentials, contact your database administrator or IT department.
| Field Name | Description | Example |
|---|---|---|
| Name | The name that displays in Mining Prep. | erp_production_db |
| Fetch Size | Optional. The size of chunks that Mining Prep uses to import the data. Leave blank if you are unsure. | 65536 |
| Server | The domain name or IP address of the database server. | db.example.com or 192.0.2.6 |
| Port | The port used to reach the database. The default port for Oracle is 1521. | 1521 |
| Schema | Optional. Defaults to the username. Specifies the database schema of all of the displayed tables. | public |
| Database | The database name on the server. | INVOICES |
| User | The login's username. | janedoe |
| Password | The password for the username. | ******** |
Once you've added a data source, you can import the data from this database connection into Mining Prep as a data set. There are multiple ways to import data sets from a data source:
Mining Prep can provide you with the overview of all tables and views that are available for the specific user and schema.
To import tables:
Mining Prep displays the original table names alongside an editable field. You may want to edit the table names so that they are easier to understand.
Mining Prep supports custom SQL queries to select data from your data source.
If you are performing more advanced queries on the data, such as queries beyond simple SELECT statements, we strongly suggest you create a view for that SQL statement inside your database. Then, you can import this view into Mining Prep as a table. Examples of advanced queries might include data aggregations, joins, or manipulations.
Note: We suggest creating a database user with only limited rights to access the necessary data. Mining Prep inherits the same privileges as the database user.
To query for tables:
The data source overview displays all of the imported tables.
If your data set has imprecise time stamps—for example, times that are only exact to a day and year—be aware that the order of events in your models may not appear as you would expect. This is common for SAP data. Events with identical time stamps display in the order they appear in the data set.
This can lead to more process variants which may influence the accuracy of your analysis and conformance checks.
If you want to start building your event log from your data set(s), click CREATE TRANSFORMATION PROJECT. This automatically creates a new transformation project on the Transformation Projects tab.
Go to Transform Data to learn more.