Note: Customers who wish to use Google services in Appian will need to bring their own Google Cloud credentials to do so.
Security is a top concern for businesses when considering a new technology. This page describes how your data is protected when using Appian AI for document extraction and processing. This page specifically describes how your data is treated when using Google Cloud services.
Who processes my document data? How can I decide?
Appian's document extraction process is powered by Google Cloud Document AI and Appian's native document extraction functionality. Depending on your document extraction needs, you can choose to use one or the other. The vendor you choose, as well as the way your data flows, can vary based on your requirements.
The vendor you choose to process your documents depends on two main factors:
- Security requirements: While both Appian and Google uphold strict security standards for your data, your business or industry may require data to stay within Appian. In these cases, you can choose Appian as the vendor to process your documents and the resulting data.
- Types of documents you wish to process: Appian's native processing capabilities complement Google's Cloud Document AI. Both vendors overlap in certain capabilities, but one vendor's service may be better suited to processing fillable PDFs vs. flattened PDFs, for example. To learn about PDF types and each vendor's capability process data within those PDFs, refer to Which vendor is best for my documents?.
You may also have additional requirements or preferences that determine which vendor you favor in processing documents. If you already have a Google Cloud account, you may decide to use Google's services. Non-Appian AI customers should configure additional settings during setup to use their existing Google Cloud accounts.
When does Appian need to use Google's services?
Appian's native processing capabilities complement Google's Cloud Document AI. Both vendors overlap in certain document processing capabilities. The following table demonstrates which vendor supports certain data extraction processes and tools based on the type of PDF being processed:
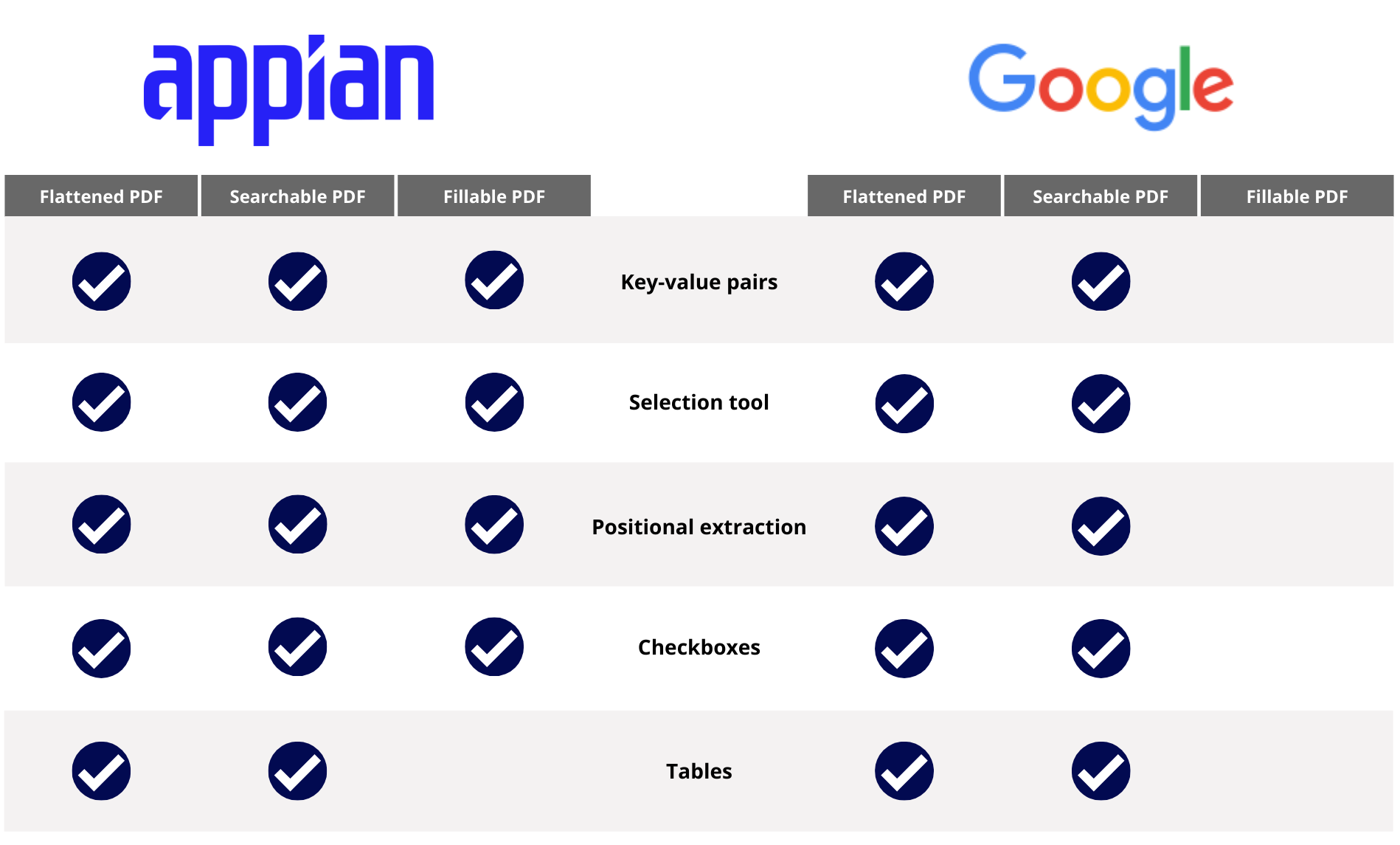
See Which vendor is best for my documents? for more information on document types and processing capabilities.
If I choose Appian to extract and process my documents, does Appian have access to the data?
No. Appian does not access customer's business data and has a strong security, privacy, and compliance posture. Visit the Appian Trust Center for more details.
How is the data stored after it's extracted and processed from my documents? For how long?
Tip: This section describes data storage practices when using Google's services.
Data storage location and duration changes based on how it's being used. The following details assume an Appian AI implementation using both Appian and Google extraction capabilities:
- Classification model training: The document is stored in a Google Cloud storage bucket when uploaded, in the supported region where storage was originally provisioned. Then the documents are converted and digitized to form a dataset to train the classification model. The model and the dataset are stored and processed in the supported location corresponding with the region of the storage bucket. The documents and their digitized datasets are deleted once the model is trained and deployed, which can take up to 24 hours.
- Document type classification: Classification sends the document to Google Cloud for AutoML Natural Language Processing. The document is stored in a Google Cloud storage bucket, in the supported region where storage was originally provisioned. Google's AutoML Natural Language digitizes and classifies the document content into user-defined categories based on a machine learning model that has been trained on a representative data set. The results are then returned back to Appian. The document is deleted after the model returns a prediction, which can take up to three minutes.
- Data extraction: The document is sent to Google Cloud Storage within your configured Google Cloud Platform project so that Document AI can be performed on it. The document is then analyzed using the Google Cloud Document AI API. This analysis data is stored in a JSON document in a Google Cloud storage bucket and sent back to Appian. For Appian AI customers, the uploaded document and JSON analysis document are deleted after 24 hours. Non-Appian AI customers will need to arrange for the deletion of the document. The auto-mapping learning of labels and values is stored in the Appian environment. The learning happens independently in each environment.
How does Appian use my data?
Appian does not access customer's business data. Appian does not share the extracted data with Google or use it beyond the customer instance. This data is not used to improve Document AI or improve mappings globally across Appian customers. The entire processing and improvements remain with and within your systems.
How does Google use my data?
Visit Google's site for the most up to date information regarding their security commitments. We've summarized some key points on the Data Security page of the Intelligent Document Processing documentation.