| Process Mining is deprecated with Appian 24.2 and will no longer be available in an upcoming release. Instead, we encourage customers to use Process HQ to explore and analyze business processes and data. |
The Insights page lets you dive deeper into your processes. You can choose between two analysis modes: Root Cause and Distribution. Switch between those two at the top of the Insights page.
The Insights page lets you investigate the discovered process, but where do you start? That depends on what type of information you're interested in:
Root cause analysis splits the available data set in respect to a deviation, duration, or follower relationship. One part of the data set contains the deviation, has a certain duration, or follower relation and the other part does not. Following attributes, their values, and their relation occurring in one of the areas are compared against each other.
Note: Filters apply to root cause analysis. Filters limit the data foundation the analysis is done on. Review your current filters to ensure you're analyzing the complete set of data you're interested in.
When you first open the Root Cause page, no results appear yet. This is because the focus must be set before an analysis can be started.
While Appian runs the root cause analysis, you can continue to use Process Mining. As soon as the analysis is finished, a message appears at the bottom of the screen, which allows you to jump directly back to the root cause analysis page.
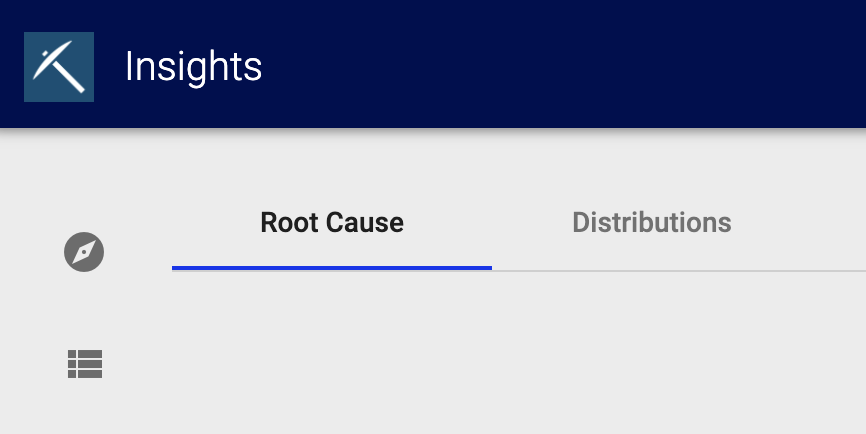
After a successful root cause analysis, the analysis results are displayed.
Root cause analysis results are divided into four sections:
The top of the results show you the parameters of your analysis request. For example, Find root causes for cases in which activity Vendor invoice: created is eventually followed by Vendor invoice: payment..

Click this statement to view the additional options you configured when starting the analysis. This creates a filter, and a corresponding filter card appears in the filter panel.
This section also displays the percentage of affected cases and the number of affected cases is shown.
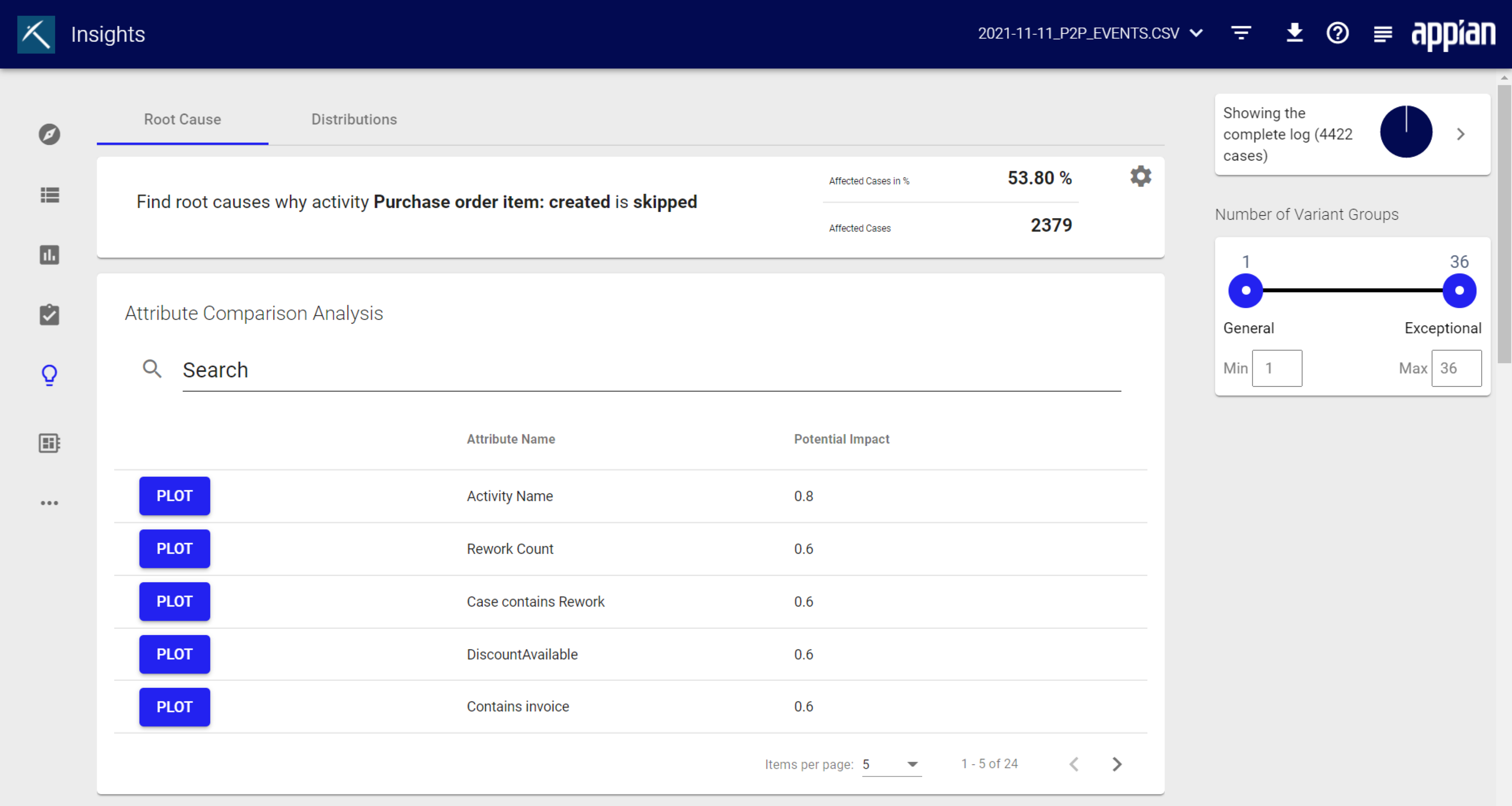
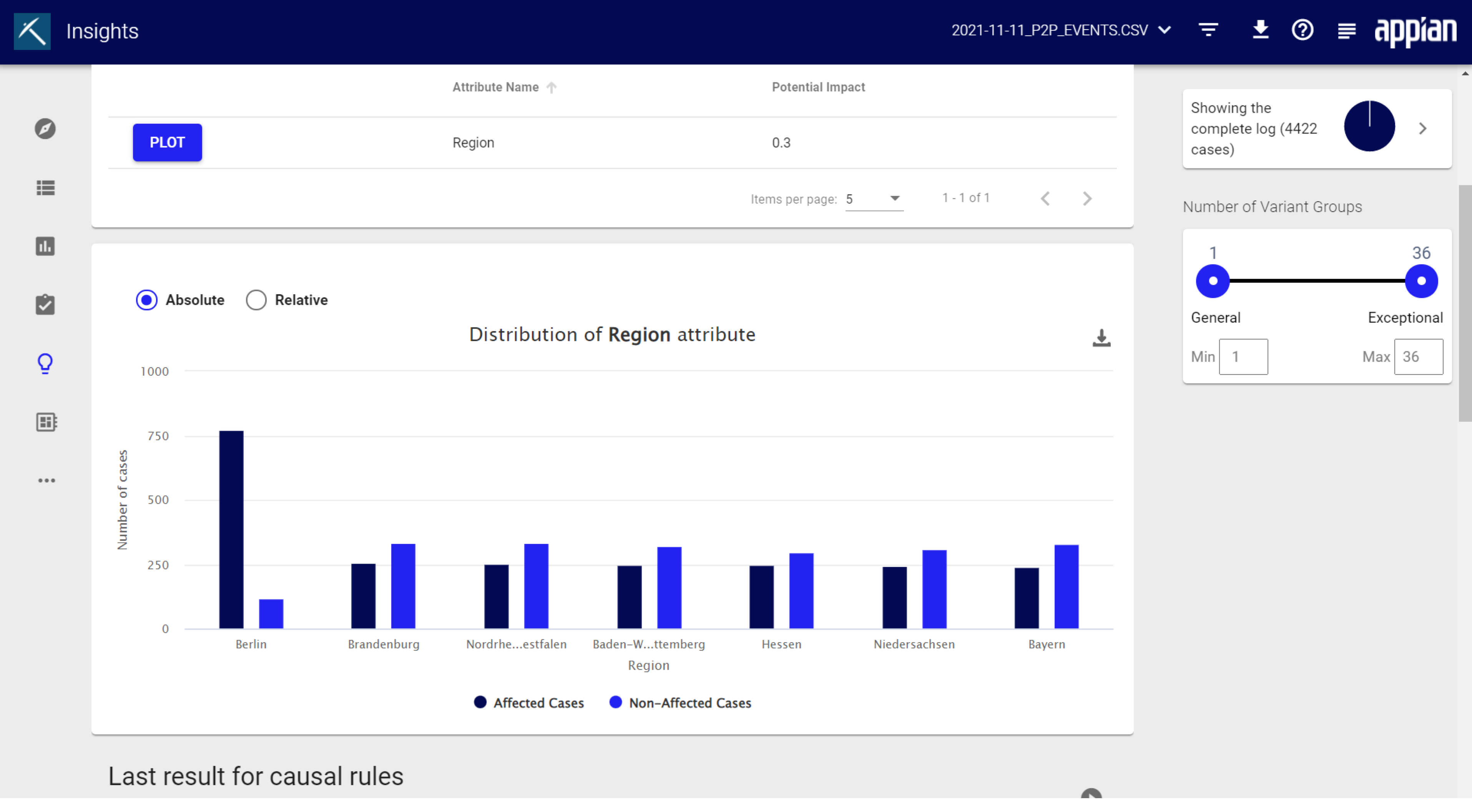
The attribute comparison analysis focuses on the occurring attribute values. It compares how often which attribute values occur in the affected area and in the unaffected area. Thus the column chart shows how distinct the attribute values are between the affected and the non-affected area. 1 means they have no overlap at all and are therefore very good indicators for a root cause.
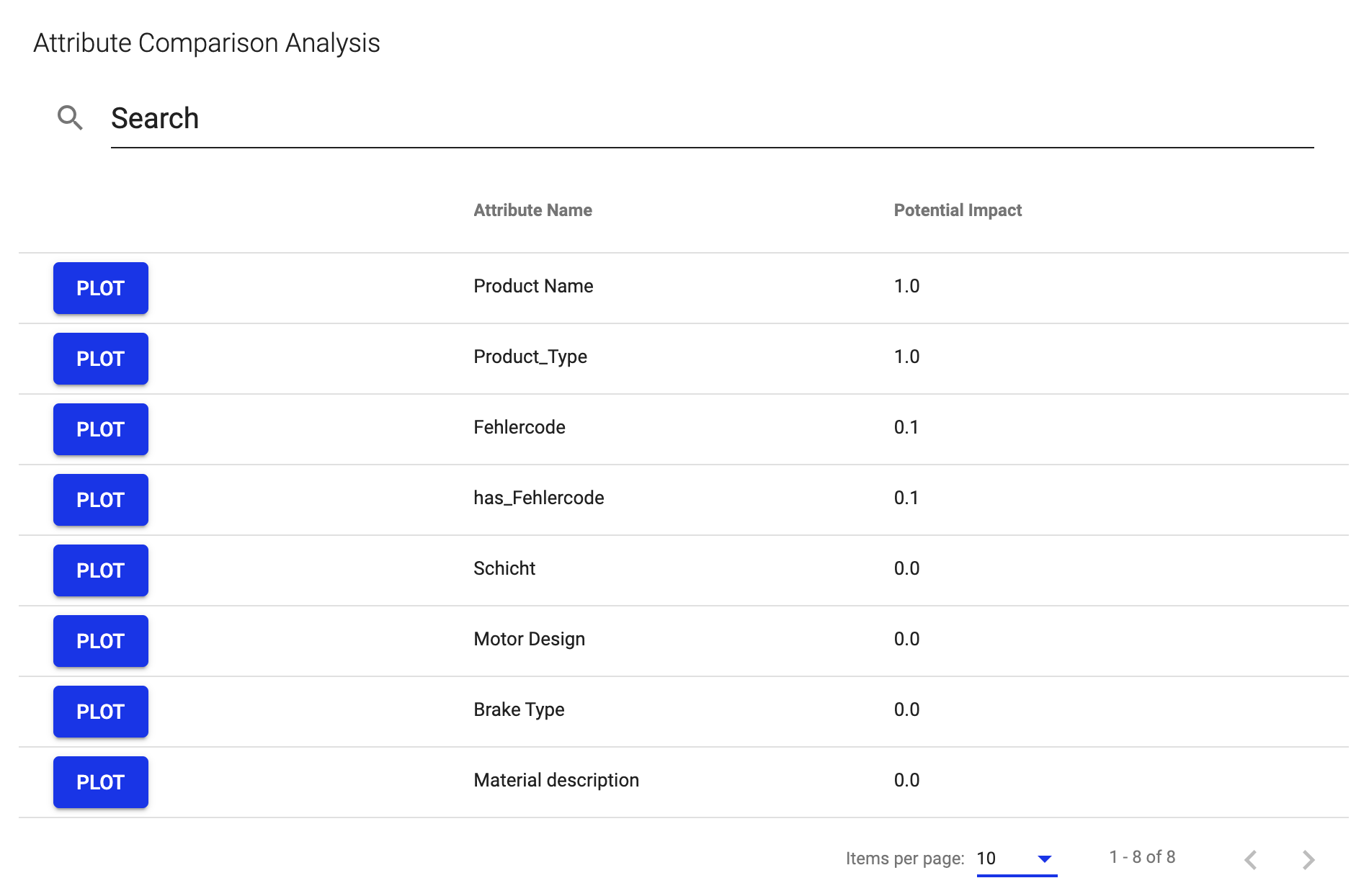
For example, if you have two countries and the value is 1 it would mean that all affected cases are only happening in one country. 0 means they have a massive overlap and there is no difference in the attribute distribution. That is, the problem would occur similarly in Country 1 and 2.
Click PLOT to see a graph of this information. You can decide whether the graph shows absolute or relative numbers. Click Download to save the graph.
This section shows common patterns in your process that might have an impact on its performance and conformance. The root cause analysis automatically identifies possible causal rules that might affect the performance of the process. A causal rule is attribute correlation that occurs more frequently in the focus area.
In addition to the rule itself, this section displays a percentage and the number of cases in the focus area that is covered by this rule. The third column also displays the accuracy of the rule. Click Show settings to exclude certain attributes. Click Re-run with current filters to see how these rules change based on excluding attributes.
Example:
The data set contains 2000 cases. The affected focus region, e.g. all cases where "Resolution & Recovery" is skipped, concerns 365 cases of the 2000 total cases processed. A rule is derived from these cases, for example costs > 6000 . This rule can be applied to a certain percentage of cases in the focus region (column 2). However, the rule found need not apply to all cases in the focus area (column 3). Therefore, the second column specifies the coverage and the third column specifies the accuracy of the rule.
If the rules found are not sufficient to answer analysis questions, click Find More Rules to identify further causal rules. Note that the rules become less accurate or cover fewer of the cases considered.
Click Show settings to see which attributes of the data set were not considered. You can also adjust which attributes to exclude from the analysis and rerun it.
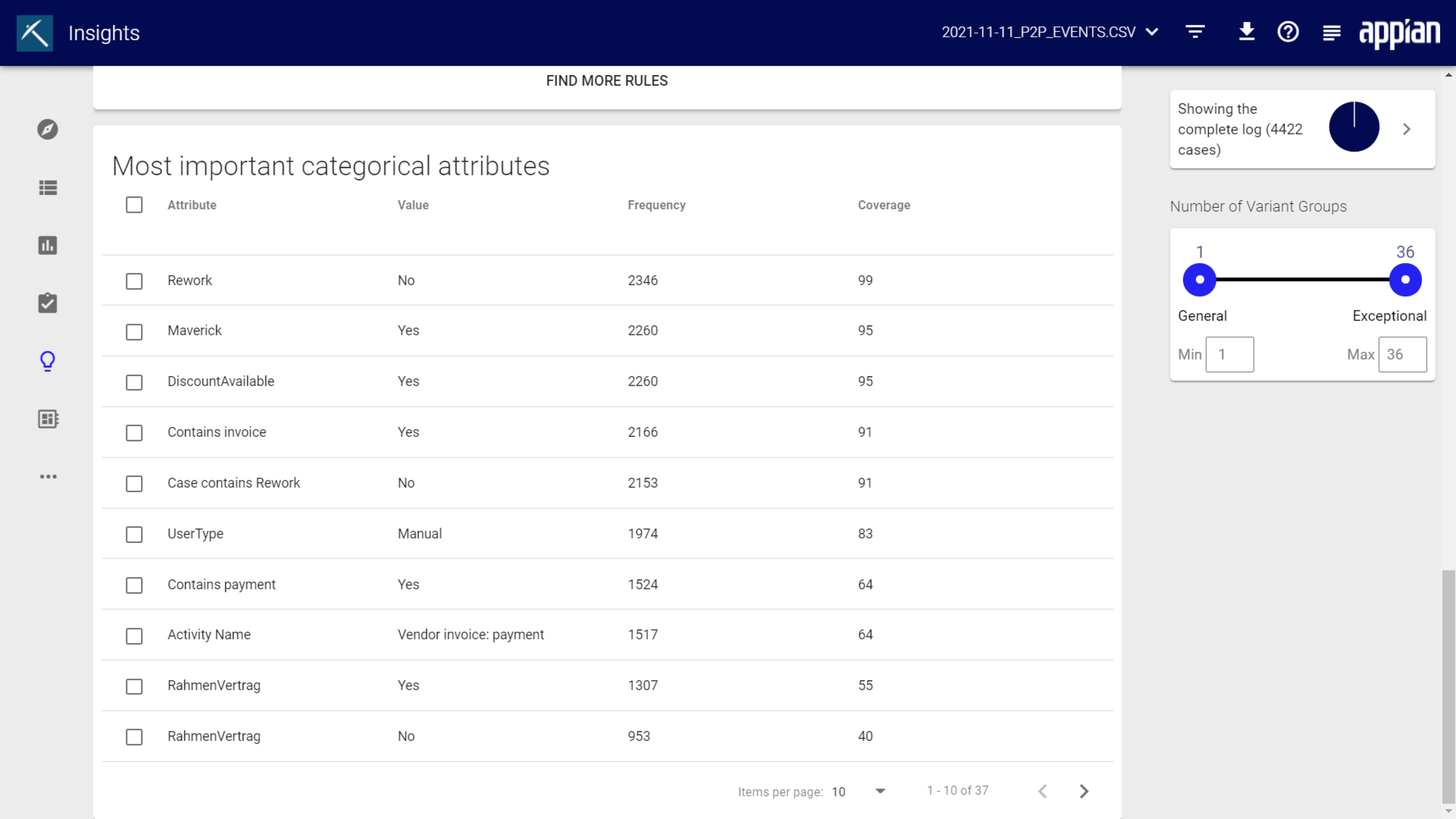
This section displays the most commonly occurring attributes, their values, frequency, and coverage in the focus area. The coverage is the percentage of cases that have this attribute/value combination.
To set one of the listed attributes as filter, select the checkbox for an attribute and click Filter selected Attribute.
Distribution analysis compares the distributions of selected activities or direct follower relations with regard to the selected attributes. Based on the selected data, the distributions for each combination of activity or direct follower relation and attribute value are calculated. Therefore, it is possible to identify if an activity or process sequence is significantly shifted for a certain attribute value.
With distribution analysis, you do not need to know the activity duration beforehand, unlike with root cause analysis. To perform distribution analysis, you need to select at least:
If your event log has start and end time stamps, you can select both activities and follower relationships; if not, you can select follower relationships to include in the analysis. In either instance, you also need to select at least one categorical attribute to include.
To start a distribution analysis:
While Appian runs the distributions analysis, you can continue to use Process Mining. As soon as the analysis is finished, a message appears at the bottom of the screen, which allows you to jump directly back to the distribution analysis page.
Tip: Analysis may take longer if you select many activities, direct follower relations, and attributes for the analysis.
The analysis results appear in a table with the following information:
To see the distribution analysis results visually, click Plot.
At the top of the Analysis results, you can: