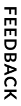| Google has deprecated legacy versions of AutoML services, which directly impacts IDP's core functionality. Additionally, the IDP application was deprecated with Appian 23.2. Customers who wish to use the application will need to refactor plug-ins using AutoML. |
Before you start using the Intelligent Document Processing (IDP) application, you will need to set up the initial configuration. Additionally, after you have started using IDP, you may want to update this initial configuration.
IDP allows members of the manager security groups to easily configure and update the configuration settings using the Configure tab.
This configuration includes:
After all of these steps are complete, users can start to classify, extract, and reconcile documents. See the User Guide for instructions on how to use the IDP site.
Because IDP classifies documents, it is important to use document types that can be easily categorized by a user. If a user can't classify a document by reading it, the AI classification model likely won't be able to either. For example, a human reader that is familiar with invoices and purchase orders would be able to easily classify them based on the information they contain.
Also, make sure you understand the documents that work best for document extraction by referring to the Appian Document Extraction page.
If you have previously configured your document channel with dummy documents or document types, we recommend having the application administrator reset the configuration.
To reset the configuration:
dudocchannel database table, for the document channel you are configuring, update the following values:
modelid: NULLmodeltrainedon: NULLnumdocsfortraining: 0invalidtypeincludedinmodel: 0dudocunderstanding database table, delete all of the rows where the channelid matches the channelid of your document channel.Before you get started, we recommend making sure the latest version of the IDP application is installed.
The latest version of IDP is version 1.8.
Compare the latest version with the application version displayed in the ABOUT tab. If the installed version is behind the latest version, contact your application administrator about installing the latest version.

By default, the application includes Invoice, Purchase Order, Claim, and Receipt document types. If you need to extract more or fewer fields than what is available out of the box for these document types, see Modifying Fields for Document Types. If you need to extract data from different document types than what is provided out of the box, see Adding a Document Type. If you need to add a new document channel, see Adding a Document Channel.
Whether you are configuring the application for the first time, or updating the configuration settings, you will access the configuration settings on the CONFIGURE tab.
Keep in mind that only system administrators and members of certain groups have access to the CONFIGURE tab. If you don't see the tab, contact the application administrators. See the Groups Reference Page for more information about what actions the different user groups can take in IDP.

Whether you are running the configuration for the first time, or editing an existing configuration, you will see the current configuration settings in a grid. To edit the configuration, click the edit icon ![]() in the right-most column of the grid.
in the right-most column of the grid.
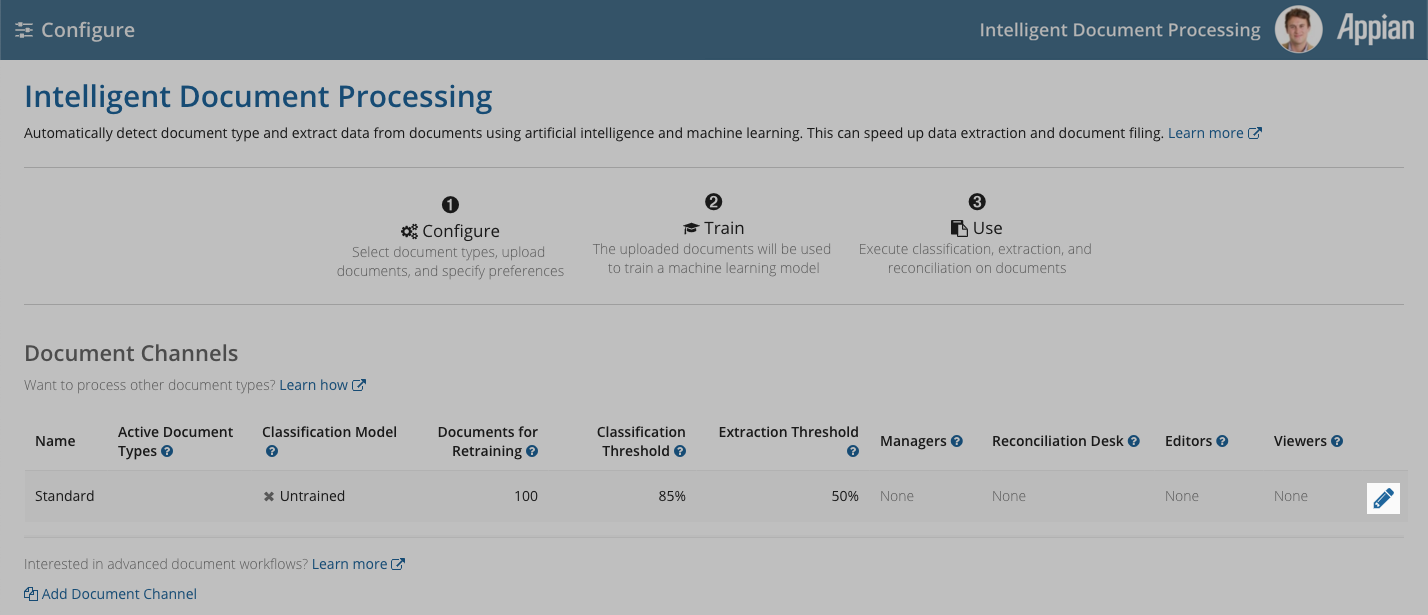
The next step in configuring IDP is to select whether you need to process multiple document types and need IDP to classify them, or if you only need to extract information from one document type.
If you only need to process one document type, you can skip training the classification model by selecting the extraction-only workflow. You will be able to start processing documents as soon as the configuration is complete, rather than waiting for the classification model to be trained.
To select the channel workflow type:

Now you will select the document types that you want to process.
By default, the application includes Invoice, Purchase Order, Claim, and Receipt document types. If you need to extract more or fewer fields than what is available out of the box for these document types, see Modifying Fields for Document Types. If you need to extract data from different document types than what is provided out of the box, see Adding a Document Type.
To select the document types:
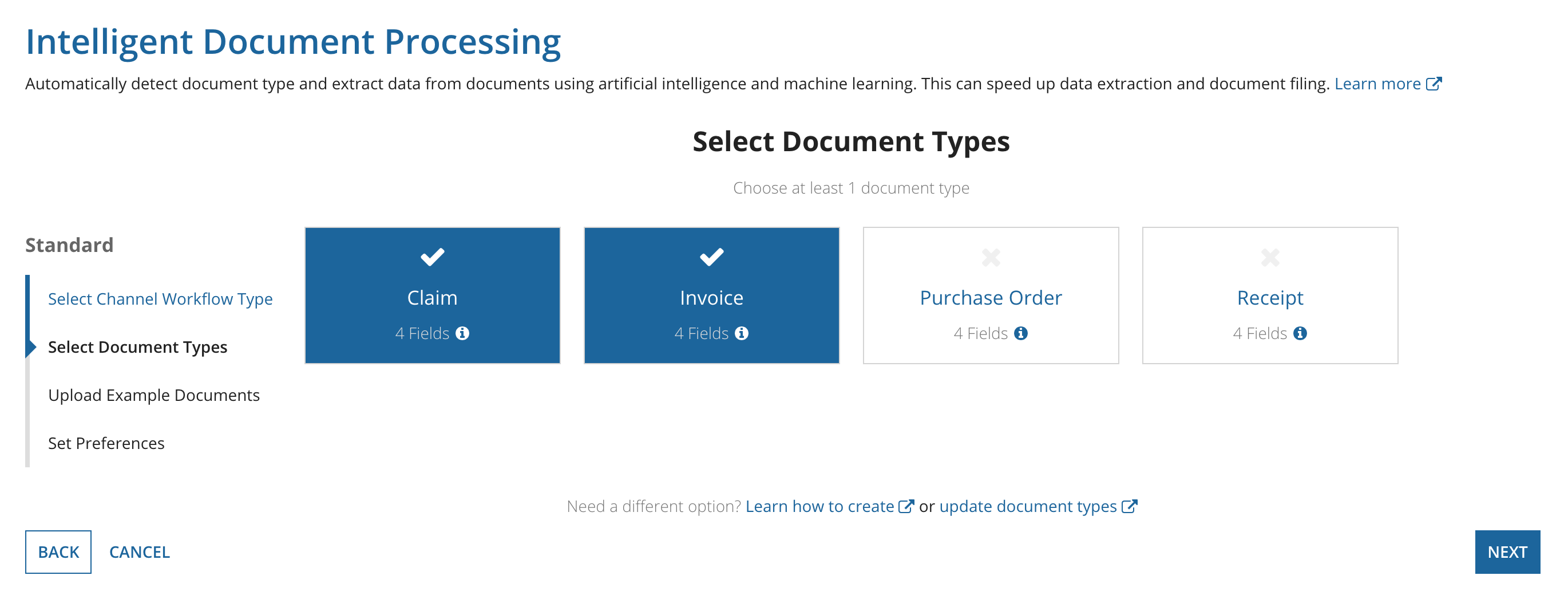
If you chose Classification and Extraction in Step 2, you will need upload example documents to train the AI classification model to learn the characteristics that are common for each document type. Keep in mind that this process only trains the classification model. It does not affect the document extraction.
The documents you upload must be ZIP files containing PDFs.
When you are collecting documents to upload for training, choose a representative set of the actual documents that you will want to process. The better this sample set matches your actual documents, the better the classification model will perform.
Note: If you retrain the classification model, you will need a new set of documents for the training. If documents are the same or too similar to documents that were previously uploaded, the process model might encounter an error during the training and time out.
To upload your example documents:
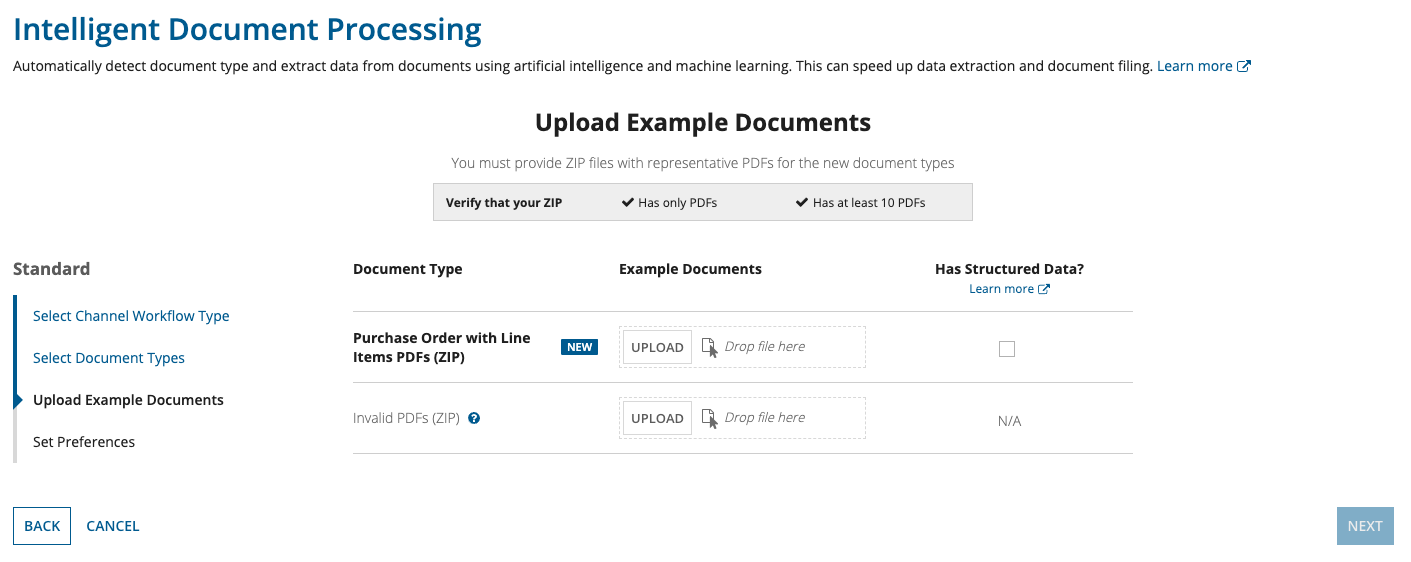
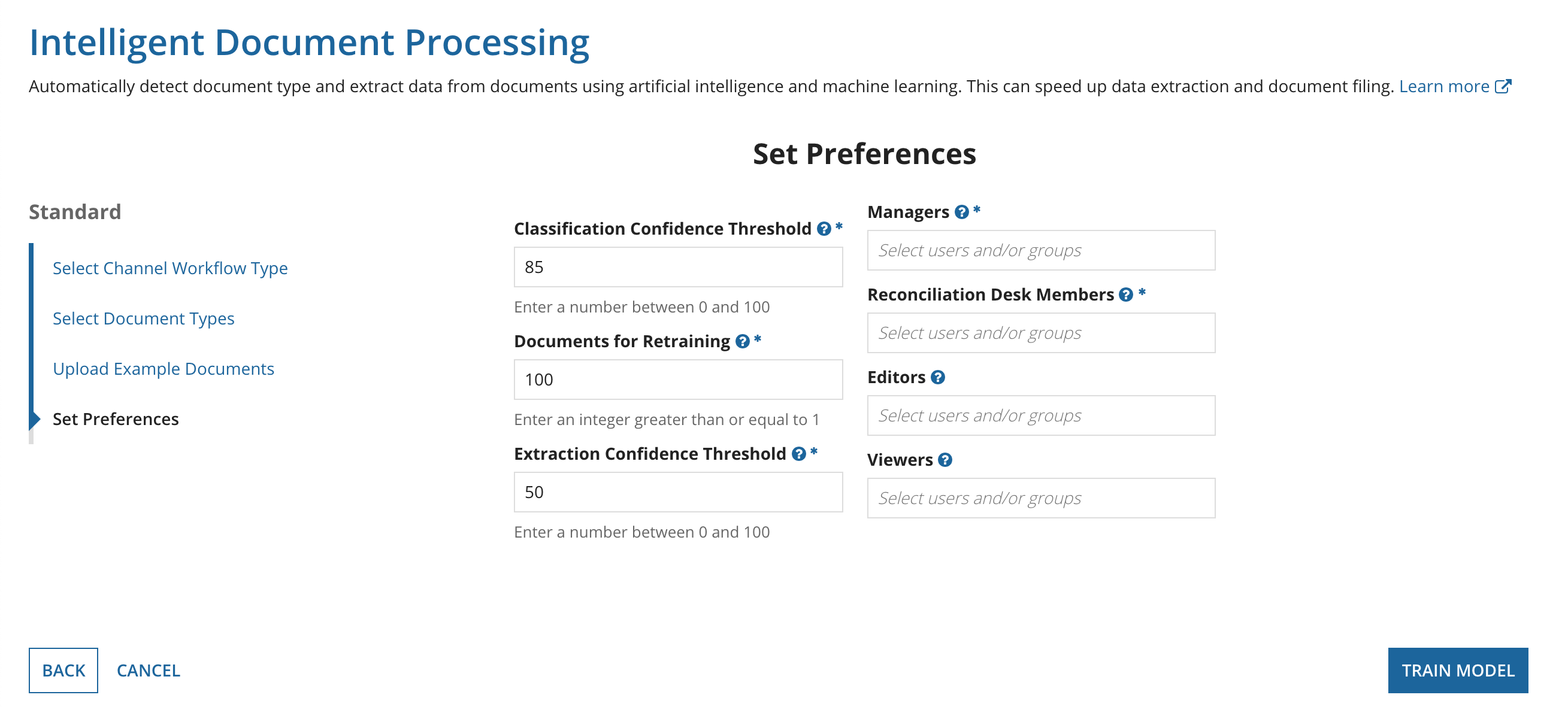
The final step is to set the preferences for your configuration. Note that if you chose Extraction in Step 2, some fields in the Set Preferences page will not display since they don't affect extraction-only workflows.
After you set these preferences, you can start the training for the AI classification model.
Tip: To determine an appropriate confidence threshold, it may be helpful to understand a couple of concepts.
A confidence interval is a range of plausible values for an unknown parameter.
The confidence interval has a confidence level that the true parameter is in the proposed range.
If a prediction has a 95% confidence level, then it has a 95% probability of containing the true parameter. If the confidence level meets the confidence threshold, then the document will be auto-classified.
To set the IDP preferences and start the training:
If you chose Extraction in Step 2, users can start uploading documents right away.
If you chose Classification and Extraction in Step 2, the classification training will begin. The training can take several hours. You will receive an email when the training is complete. Once the training is complete, users can start to classify, extract, and reconcile documents. See the User Guide for instructions on how to get started using the application.
If there is an issue with the classification model training, contact your application administrator who can follow the troubleshooting steps.
If you receive an email notification about an error with the classification model training, refer to the table below to troubleshoot the cause of the error.
After you have determined the cause of the error:
DU Configure Document Understanding process instance.
| Issue | Resolution |
|---|---|
| There was an error when uploading the dataset CSV file. |
|
| There was an error when creating the training dataset. |
|
| There was an error when importing the training dataset. |
|
| There was an error when deploying the model. |
|